enechain では、電力業界における膨大なデータを処理する際に非同期処理を頻繁に利用します。
私たちのチームでは、非同期処理を実現するにあたって PubSub を使ってイベントドリブンな処理を行っています。今回は enachain でどのように非同期処理を設計し、実装時にどのような工夫をしているのかを紹介します。
非同期処理の設計
私たちのチームでは、実装前に以下の観点でレビューを行ない、全体を設計しています。
- 処理の全体像はどうなっているのか?
- Pull 型が良いのか Push 型が良いのか?
- どのくらいの時間がかかる処理なのか?
- どのくらいの時間内に処理を完了する必要があるのか?
- どこに負荷がある処理なのか?
- 画面上の表示をどのようにするのか?
1. 処理の全体像はどうなっているのか?
チームメンバーが全体像を知り、認識を揃えて合意を得るために、下記のような簡易的な図を書いています。
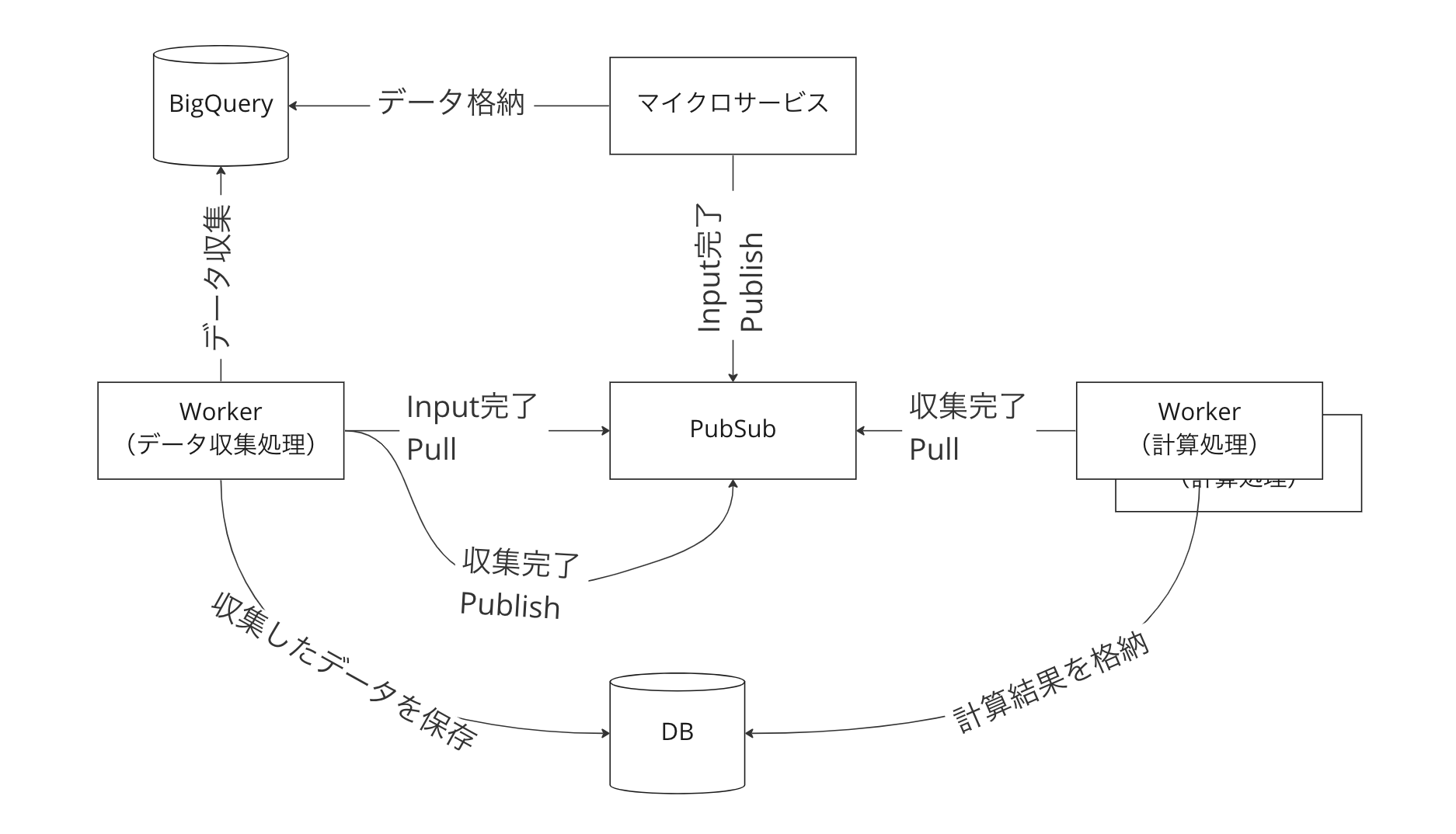
これを俯瞰して見ることで、設計者とレビュアーがお互いにどのような構造を作るのか認識を揃えた上で話し合いをすることができます。
この図を見て、処理の単位が正しいのか(例えばデータ収集処理と計算処理が一緒の方が良いのではないか?など)、Pull 型と Push 型のどちらがいいのかやそもそも PubSub を使うのが妥当かなどを話し合います。
例えばデータ収集から計算処理までを一連の流れにして、CronJob にしてしまえば良いのでは?というのを運用の観点も含めてチーム内で話し合いをします。
もし処理の単位が大きすぎるのでは?という意見があれば適切な単位に分けて作るようにします。
2. Pull 型が良いのか Push 型が良いのか?
Pull 型と Push 型のどちらを使うかは下記のような使い分けをしています。
- 認証処理を必要としない、Timeout の設定範囲内で終わる、負荷の心配がない処理であれば、エンドポイントを使う前提の場合には Push 型を使う
- Web サーバで処理できないものは Pull 型を使い、worker から PubSub のキューを取得する
Push 型の場合には Web サーバで受けることになるので、既存の Web サーバの認証周りをパスする特殊なエンドポイントを作成するか、認証を省いて Timeout の設定も長めにとった PubSub 専用のサーバで受けるのかも考えて使う必要があります。
Pull 型の場合は worker を用意し、worker 内から PubSub のキューを取得するため、Push 型に比べて比較的セキュアに作りやすくなります。
私のチームでは、既存の Web サーバに特殊な設定を入れたくないのと、メンテナンスの時に Push されても困るため、自分たちの都合で制御がしやすい Pull 型を選択しています。
3. どのくらいの時間がかかる処理なのか?
Subscription の確認応答期限 (Ack Deadline) を超える時間が想定される場合には PubSub を使って処理するのに向いていない可能性が高いです。
PubSub では最大の確認応答期限が 10min であるため、それを超えると再送されてしまうため処理を分割するなどして短い期間の処理に分けるか、全く違う形式を検討した方が良いでしょう。
4. どのくらいの時間内に処理を完了する必要があるのか?
ビジネス要件によっては遅延があまり許されないことがあります。
その場合は並列数を上げる、処理を分割して処理をすぐに完了するといったことが必要なことがあります。
そのため、前提となる要件を確認しておき、どの程度の並列数で実行する必要があるのかを決めておきます。
5. どこに負荷がある処理なのか?
オートスケールの設定やマシンスペックを調整するための情報として、DB、処理をするサーバ、連携して動くマイクロサービスなどなど、どこでどのような処理を行うのかを洗い出しています。
予測ができないところは実際に処理の実装のみを行い計測するか、多めに見積もっておいて既に動いているサービスに影響が出ないようにしています。
もし DB の select で過剰な負荷がかかることが想定される場合には、専用のリードレプリカの用意を検討するなど、負荷がかかる前提の備えをします。
6. 画面上の表示をどのようにするのか?
CSV ダウンロード用のデータ生成を行うような場合と、メールなどのユーザに届くものを処理する場合では、画面上の扱いが変わってきます。
メールの場合には受信時にユーザが気づくことができますが、データを生成する処理を行う場合などにおいては画面上になんらかの表示をするか通知が飛ばないとユーザが現状を把握する術がありません。
そのため WebSocket やポーリングなど、何かしらの手段を使って画面上にユーザに気づかせる手段を作った方が好ましいと思われます。
ポーリングを行う場合には Web サーバに負荷がかかることも考えられるため、API などで負荷がかかるポイントがあるのかを先に考えておくと、後で手戻りが発生するリスクを減らすことができます。
非同期処理の実装
運用上で困らないように工夫しているポイントを紹介します。
オートスケール
enechain では worker は kubernates 上で動いているため、HPA の機能を使ってスケールさせるような作りにしてあります。
具体的には、worker を下記のように Deployment の manifest で作成し、HPA を利用してスケール可能にしてあります。
我々のチームではまだスケールさせたいという要件はありませんが、後々 CloudMonitoring などと連携をしてキューの数が一定数以上になった時にスケールさせることができる前提にしてあります。
また、デプロイ時に完全に新しいロジックで動いてほしいために、あえてストラテジを Recreate にして一時的に worker の処理が止まることを許容しています。
apiVersion: apps/v1 kind: Deployment metadata: name: enechain-worker labels: app.kubernetes.io/name: enechain-worker app.kubernetes.io/component: worker app.kubernetes.io/part-of: enechain spec: replicas: 1 revisionHistoryLimit: 5 selector: matchLabels: app.kubernetes.io/name: enechain-worker app.kubernetes.io/component: worker app.kubernetes.io/part-of: enechain strategy: type: Recreate template: metadata: labels: app.kubernetes.io/name: enechain-worker app.kubernetes.io/component: worker app.kubernetes.io/part-of: enechain 〜〜〜以下省略〜〜〜
冪等性の担保
PubSub では完全な冪等性は担保されていないため、常に処理する側で冪等性を持たせる必要があります。
Pull 型であれば一回だけ処理されることは保証されていますが、これも確認応答期限を超える場合にはその限りではなく、再送されてしまうために冪等性がなかった場合には二回処理が走ることが考えられることに注意します。

何回実行されても結果の変わらない、例えばランキングの生成のようなケースでは既に冪等な状態であるので必ずしも冪等性を担保する必要はありません。
ですが課金処理のような金額を多く取ってしまうなどの可能性がある場合には、二回処理が実行されることを許容できないために冪等性を持たせておかないと過大請求が発生してしまいます。
このような事業的に許容できない特性を持つ処理を行う時には必ず冪等性を担保するようにします。
冪等性の担保の方法
冪等性の担保の方法として、Redis や DB などを使って今現在実行中であるのかを判定して、二回実行されないような仕組みを作る方法があります。
DB で実現する場合には TransactionLock を利用した(RollBack が発生するとステータスが巻き戻ることに注意)ステータスによる状態管理、Redis の場合には実行中ステータスをユニークなキーで保存し、実行中であればスキップするなどの対応をします。
そのステータスを処理を開始する時点で確認してから実行するようにするため、ベースクラスなどを用意して共通化しておくと運用も楽になります。
ただし、上記のようなステータス管理をした場合には、処理が失敗した時に未完了ステータスで止まっているものが発生するため、一定時間以上ステータスが変わらないものはウォッチする必要があります。どのようなパターンがあって、どのような運用が必要になるのかはよく議論しておくことが重要です。
画面上の表示で状態把握
長時間かかる処理を流している場合には、今現在のステータスを知ることが出来ないと利用者は不安になってしまいます。
私のチームでは、ステータスを DB で管理しておき、画面がリロードされても確実に状態がわかるようにするなどの工夫をしています。
エラートレース用のログ
非同期処理をキックしている時やキューが複数のイベントに分割されている時など、どこからどのように処理が行われているか、一連の流れを通じてログが追えないと、エラーが発生した時に調査に時間がかかってしまいます。
私のチームでは、下図のように全てのイベントで同じ Id をログに落とすために、処理の起点となるポイントで生成された TraceId を伝搬させています。このようにすることで、DataDog などで TraceId でログを検索すると全てのログを時系列順で追えます。

最後に
今回は私が所属するチームでの非同期処理の設計や工夫について紹介してみました。
単純に非同期処理と言っても、作った人しか知らないということが発生したり、エラーが発生した場合にどういう対応をすればよいのか、どこから調べればよいのか分からなくなったりと、個人スキル依存になりがちです。
そのため、今回の記事のようにチームでレビューをできる、みんなの認識を合わせて運用ができるということを大事にしながら開発を行っています。
これから非同期処理をやってみようとしている人の参考になれば幸いです。
enechain では一緒に働くメンバーを募集しています。
興味がありましたら是非ご応募お待ちしております。