

はじめに
こんにちは。enechainで統計・機械学習モデルの構築やLLM(大規模言語モデル)の活用推進を担当している@udon_tempuraです。
近年、GoogleのGeminiなど生成AIの発展が目覚ましく、多くの企業がこれらの技術を業務に取り入れようとしています。 私たちenechainも例外ではなく、積極的にLLMの活用を進めています。
今回はその活用例の1つとして、複数のLLMを使い分けて構築した「会議動画の要約作成ワークフロー」についてご紹介します。 このワークフローでは会議の録画をインプットとして、以下画像のようなアウトプットの生成を目指します。

この取り組みを通じて得られた知見や課題が、同様の挑戦をされている方々にとって有益な情報になりますと幸いです。
背景と課題
enechainは、あらゆるエネルギーの価値を自由に取引できるプラットフォームを運営しており、電力などの先物商品を取り扱っています。 エネルギー業界は規制が多く、また市場の変化も激しいため、最新の業界動向や規制の変更をタイムリーに把握することが極めて重要です。
そのため、私たちは政府の専門会議や業界団体の会合などを常にウォッチし、その内容を社内外で共有する必要があります。 しかし、これらの会議は通常、動画のみが公開され、文字起こしや要約は提供されません(会議例)。 そのため、内容を効率的に共有するためには、自分たちで文字起こしと要約を作成する必要があります。
ここで問題となったのが、作業にかかる膨大な時間です。 これらの会議動画は往々にして数時間に及び、その全てを聞き、文字に起こし、さらに要約すると、1つの会議資料を作成するのに2日ほどかかっていました。 文字起こしや要約に関しては商用のツールもありますが、エネルギードメインの複雑な用語の認識や要約精度に課題があり、大幅な工数削減は難しいのが実情でした。 このような状況では、タイムリーな情報共有が難しく、また担当者の負担も大きくなってしまいます。
システム概要
この課題を解決するため、私たちは複数のLLMを統合した自動要約ワークフローの構築に取り組みました。システムの設計にあたっては、以下の点を重視しました。
- 非エンジニアでも操作可能な使いやすさ
- 迅速なPDCA(計画・実行・評価・改善)サイクルが実現できること
- 過去の要約データの効果的な活用
これらの要件を満たすため、私たちは以下のツールを選択しました。
- Google Colab:Python実行環境
- Google Spreadsheet:過去の要約データの保存と参照
- Google Docs:最終的な要約文書の作成と編集
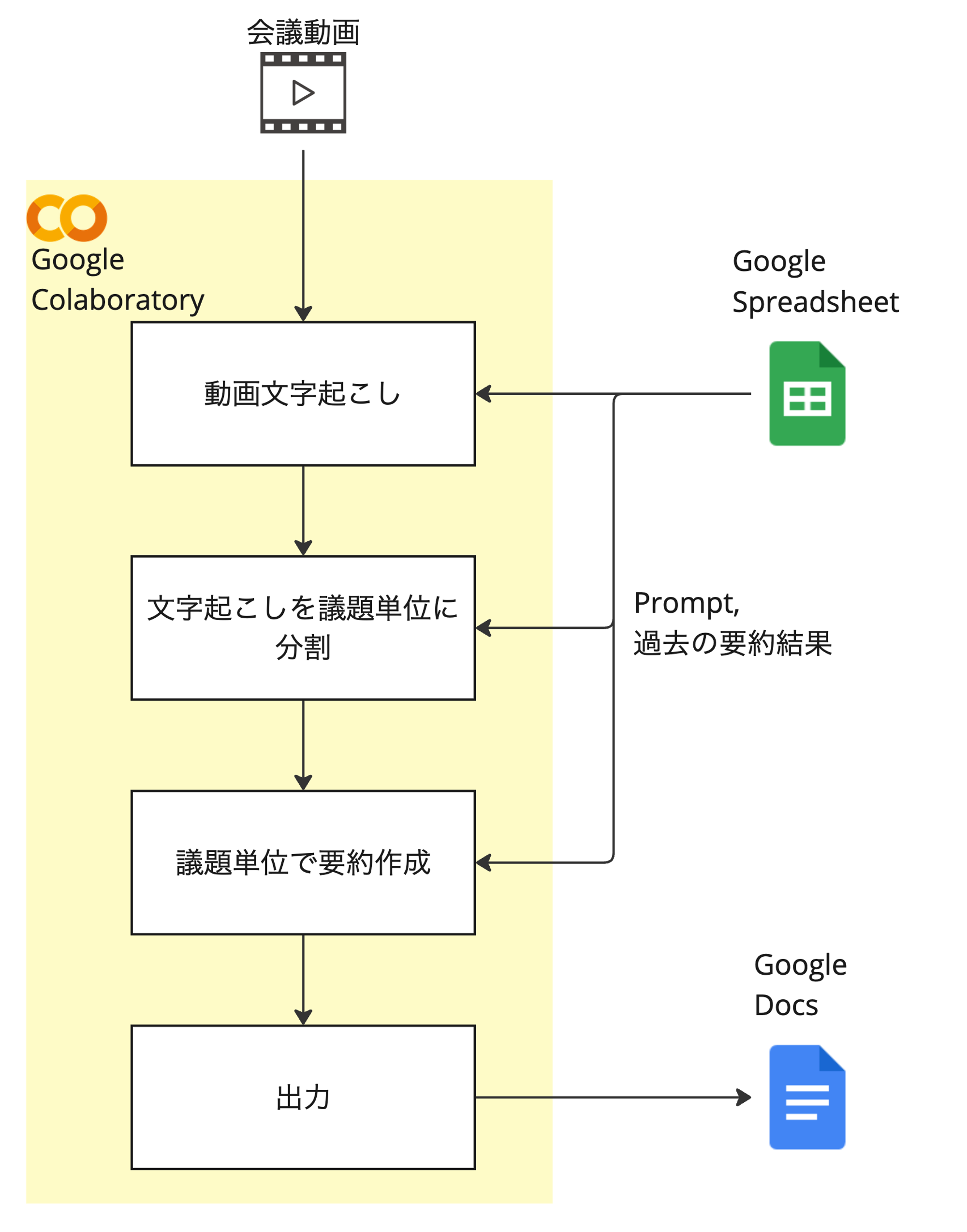
この構成により、エンジニアでなくても一定の操作が可能となり、また必要に応じて人間による修正や確認を挟むことができるようになりました。
ワークフローの詳細
それでは、構築したワークフローの詳細について説明していきます。
動画文字起こし (Gemini, GPT-4o)
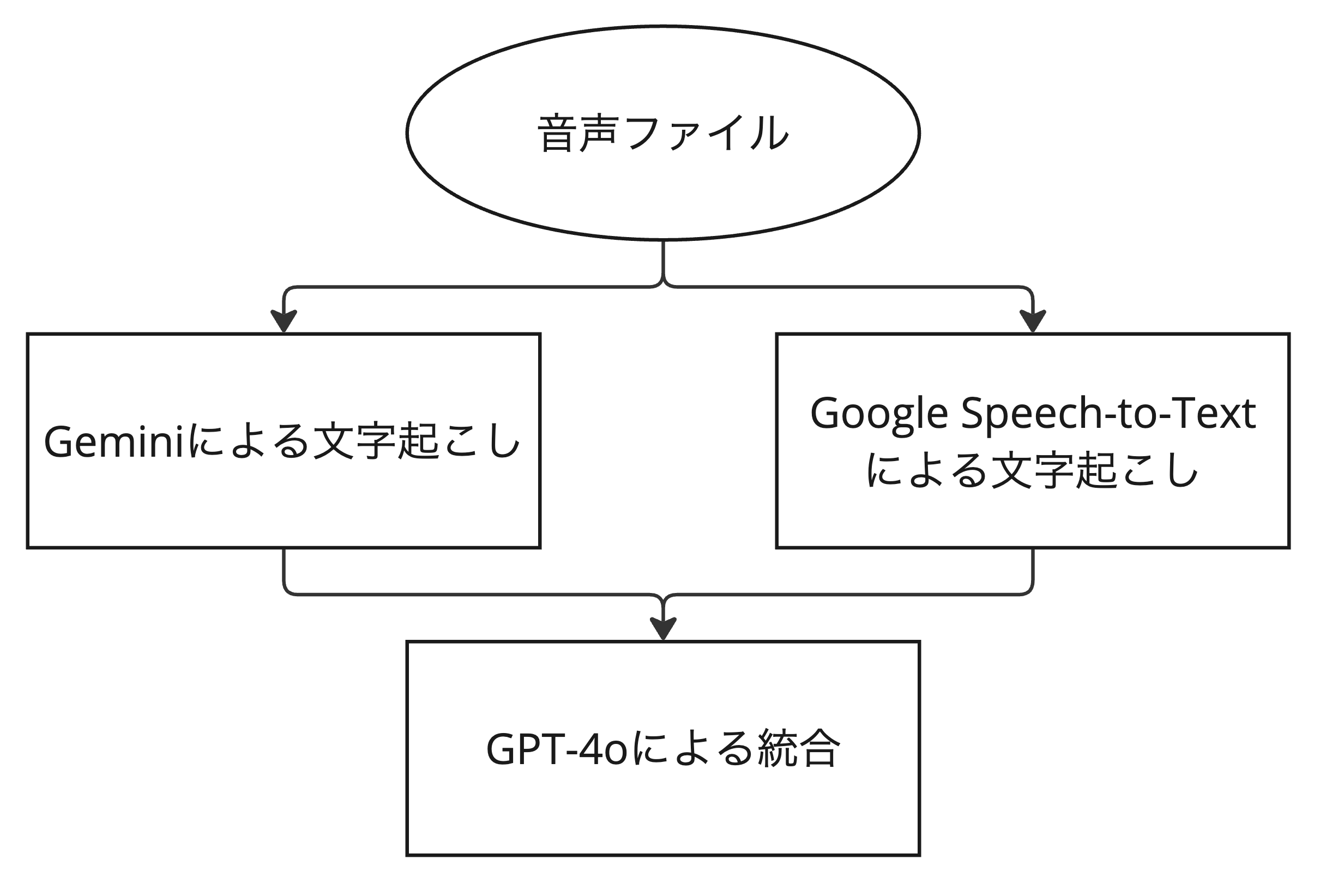
文字起こしでは、GoogleのGemini 1.5 ProとGoogle Speech-to-Text APIを併用しています。 当初はSpeech-to-Text APIのみを使用しており、頻出語句の辞書をAPIに渡すことで専門用語を高い精度で認識できましたが、コンテキストを考慮した語句認識に課題がありました。 一方、Geminiはコンテキストの理解に優れていますが、専門用語や細かい口調の再現ではSpeech-to-Text APIに及びませんでした。
そこで、両者の長所を活かすため、それぞれのAPIで文字起こしを行い、その結果をLLMで統合するアプローチを採用しました。 比較検証の結果、文字起こし中の細かい数字の認識が優れており、その他の統合の品質でも問題がなかったGPT-4oを統合用のモデルとして採用しています。 これにより、高い認識精度と文脈理解の両立を実現しています。
文字起こしの議題単位の分割 (Claude 3.5 Sonnet)
次に、文字起こしされたテキストを議題ごとに分割します。この作業にはAnthropicのClaude 3.5 Sonnetを使用しています。
LLMは大量の出力を生成する際、結果が変動しやすく不安定になる傾向があります。 そのため、会議全体を一度に要約しようとすると、重要な情報が欠落したり、不適切な要約が生成されたりするリスクがあります。
この問題を軽減するため、会議の議題単位に文字起こしを分割し、後の要約処理の範囲を絞り込むようにしました。具体的には以下のような工夫を施しています。
文字起こしの各行の先頭に番号を付与
[1]第N回 XX検討会を始めたいと思います。 [2]進行を務めますYYです。よろしくお願いします。 [3]本日はご多忙の中、〜〜〜Claudeに対して、議題の変わり目を示す番号を抽出するよう指示
あなたは文字起こしのセクション分けをするために、各セクションの先頭の文章の番号を抜き出すアシスタントです。 以下に文字起こしを与えます。 {mojiokoshi_text} ## 議論の構成 1. 冒頭の挨拶 2. 議題1の説明 3. 議題1に関する参加者のコメント 4. 議題2の説明 5. 議題2に関する参加者のコメント ... ## 出力形式 【冒頭の挨拶】 <冒頭の挨拶の先頭文章の番号> 【議題Nの説明】 <議題Nの説明の先頭文章の番号> 【議題Nの参加者のコメント】 <コメントの先頭文章の番号> ... Nは議題の数だけ存在するので議題の数このセクション分けを繰り返してください。 ## 制約 - 資料説明よりも前にコメントが来ることはありません。 - 議題の数は議論会によって異なりますので適切に設定してください。 各セクションの先頭の文章の番号を抽出してください. 出力は上記の出力形式に従い、番号以外の情報は含めないでください。抽出された番号を基に、Pythonスクリプトで文章を分割
この方法により、LLMの出力トークン数を抑えつつ、安定した議題分割が可能になりました。
議題単位での要約作成 (Claude 3.5 Sonnet, GPT-4o)
分割された各議題について、要約を作成します。 この段階では、会議で使用された資料と議題単位の文字起こしをインプットとし、過去の類似議題の要約をサンプルとしてFew-shot Learningを実施します。
ここでも複数のLLMを使用しています。具体的には、Claude 3.5 SonnetとGPT-4oの2つのモデルで要約を生成し、それぞれの長所を活かすようにしています。 例えば、Claudeは文脈理解に優れていますが、文章中の数値抽出は不十分な場合があります。 一方、GPT-4oは数値の扱いには優れていますが、詳細な説明を欠く場合がありました。
そこで、両モデルの出力を別のプロンプトを用いて統合し、より質の高い要約を生成するようにしています。 比較検証の結果、複雑な論理構造の理解に最も秀でていたClaudeを統合用LLMに採用しました。 これは機械学習におけるアンサンブル学習の考え方から着想を得て実装しました。
あなたは複数のLLMの生成結果を統合し、最適な要約を作成する専門家です。
2つの異なるLLM出力を評価・統合し、最終的に元資料との整合性を確認して最適な要約を作成してください。
## 評価基準
1. 論点の正確性
2. 論点の完全性
3. 誤字脱字の少なさ
4. 過不足なく数値抽出できているか
## 入力データ
- GPT出力 : {output_gpt}
- Claude出力 : {output_claude}
~ (中略) ~
上記の指示に従い、2つのLLM出力を評価・統合し、最適な要約を作成してください。
出力
最後に、生成された要約をGoogle Docsに出力します。Google Docsを選択した理由は主に2つあります。
- 必要に応じて人間が細かい編集を加えられること
- 編集履歴を後から確認できること
これにより、LLMによる自動生成と人間による微調整のバランスを取ることができます。
実装上の工夫と課題
このワークフローを構築する過程で、いくつかの重要な学びが得られました。
まず、モデルの変更に対して堅牢な仕組み作りの重要性です。 実際、このシステムの構築中にGPT-4oやClaude 3.5 Sonnetが発表され、モデルの入れ替えが必要になりました。 AIの進化は急速であり、新しいモデルは往々にしてそれまでの問題を一気に解決するインパクトを持ちます。 そのため、モデルを簡単に置き換えられるよう、参照部分を疎結合に設計することが重要だと学びました。
次に、完全な自動化を目指しながらも、要所要所で人間の修正を挟める設計にすることです。 AI技術は日々進歩していますが、まだ人間の判断が必要な場面は多々あります。 投資対効果を考慮すると、完璧を目指しながらも、現時点で対応が難しい部分については適切な修正ポイントを設けることが重要です。
また、複数のモデルを利用することのトレードオフについても考慮しました。 複数モデルの利用はメンテナンスコストを高めますが、単一のモデルでは要求品質を満たせない場合があります。 そのため、品質と保守性のバランスを慎重に検討する必要があります。
結果と今後の展望
このワークフローの導入により、従来2日がかりだった会議要約作成の業務が数時間で完了できるようになりました。 これは大きな成果であり、情報のタイムリーな共有と担当者の負担軽減に大きく貢献しています。
しかし、まだいくつかの改善の余地も残されています。
評価の自動化
現状、生成された要約の品質評価は人間が行っています。 LLMを評価者(LLM-as-a-judge)として使用することも試みましたが、業界特有の暗黙知や慣習の理解が難しく、十分な結果は得られませんでした。 この部分の自動化は今後の大きな課題の1つです。
実験管理などのインフラ整備
複数のLLMを使用し、様々なプロンプトやパラメータを試行錯誤する中で、実験管理の重要性を痛感しました。 どの設定がどのような結果をもたらしたかを追跡し、再現可能な形で管理するためのインフラ整備が急務です。
モデルの特性理解と適切な使い分け
各LLMには得意・不得意があり、それらを深く理解し適切に使い分けることが重要です。 例えば今回のケースでは、Geminiはマルチモーダル処理に強みがあり文字起こしは非常に強力ですが、文章要約はClaudeが優れていました。 このようなモデルの特性をより深く理解し、タスクに応じて最適なモデルを選択する必要があります。
おわりに
今回ご紹介した会議要約作成ワークフローは、LLMを活用した仕組みを実用化できた大きな一歩となりました。 技術の進歩は日進月歩であり、今後も新たなモデルや手法が開発され続けます。 私たちはこれからも最新の技術動向をキャッチアップしながら、より効率的で高品質なシステムづくりに取り組んでいきたいと考えています。
enechainでは、LLMに限らず、統計・機械学習モデルを活用した様々な機能開発を進めています。 こうした取り組みに興味をお持ちの方、一緒に挑戦してみたいと思われた方は、ぜひカジュアル面談からでもお話しさせていただければと思います。 以下のリンクからご応募ください。