

はじめに
こんにちは、enechainでソフトウェアエンジニアをしている小沢です。
私が所属しているチーム(以降、eScanチーム)では、eScanという電力会社向けのリスクマネジメントシステムを開発・運用しており、その中でGraphQLを採用しています。すでにGraphQLを採用するメリット・デメリットについて様々なところで語られていますが、eScanチームでもオーバーフェッチが解消できる点、1リクエストで必要なデータをフェッチできる点などのメリットを享受するために採用しています。
今回は実際にGraphQLを採用してから2年ほど経過しましたので、運用の中で工夫してきたことや、実際のプロダクト開発で感じた良かった点や難しかった点などの振り返りをご紹介します。
技術スタック
eScanチームの取り組みや振り返りについてお話する前に、まずプロダクトの技術スタックについてご紹介します。
言語はフロントエンド・バックエンドともにTypeScriptを採用しています。バックエンドはNestJS、モニタリングにはDatadogを採用しています。 フロントエンドは、Reactを使用したSPA構成となっており、API ClientにはReact Queryを採用しています。API通信部分のコードは、GraphQL Code Generatorを利用してスキーマからAPI通信用のcustom hooksを自動生成するようにしています。

eScanチームにおけるGraphQLの使い方
実際にeScanチームで行っている取り組みについてご紹介します。
開発フローの工夫
日々の開発業務でGraphQLのAPI設計・開発をするときは概ね以下のような流れで開発しています。
- API設計に関わるメンバー全員でスキーマを設計する
- 設計したスキーマをもとにResolverとオブジェクトを作成する
- 作成したResolverに対してモックを作成する
この時点で、NestJSの依存関係に登録しアプリケーションが起動される状態になっていればスキーマファイルが生成され、フロントエンド側はクエリの実装に進むことができます。チームではここまでの作業をなるべくスムーズに進められるよう、意識して開発を進めています。
以下はサンプルコードですが、実際にこのレベルまで書いておくと開発はスムーズに進められます。モック部分は開発対象のAPIに合わせてランダムな値にしたり固定にしたり柔軟に対応しています。
@ObjectType() export class User { @Field(() => ID, { description: 'ユーザーID', }) id: string; @Field(() => String, { description: 'ユーザー名', }) name: string; @Field(() => String, { description: 'メールアドレス', }) email: string; @Field(() => Int, { description: '年齢', }) age: number; } @Resolver(() => User) export class UserResolver { constructor(private readonly userService: UserService) { } @Query(() => User) async user(@Args('id') id: string): Promise<User> { return new User({ id, name: 'test', email: 'test@example.com', age: 20, }); } @Mutation(() => User) async createUser(@Args('input') input: CreateUserInput): Promise<User> { return new User({ id: '1', name: 'test', email: 'test@example.com', age: 20, }); } } @Module({ imports: [UserModule], providers: [UserResolver], }) export class UserModule { } @Module({ imports: [UserModule, GraphQLModule.forRoot({ autoSchemaFile: true, introspection: process.env.NODE_ENV !== 'production', // production環境ではIntrospectionを無効化 }), ], }) export class AppModule { }
query { user(id: "1") { id name email age } } mutation { createUser(input: { name: "test", email: "test@example.com" age: 20 }) { id name email age } }
N+1問題の対応と注意点
N+1問題はGraphQLというと一番最初に思い浮かぶようなワードだと思います。eScanチームでもN+1問題が発生したタイミングでDataloaderを導入しました。NestJSの場合は @ResolveField デコレータで定義されたものを対象に適用しています。
@ObjectType() export class User { @Field(() => ID, { description: 'ユーザーID', }) id: string; @Field(() => String, { description: 'ユーザー名', }) name: string; @Field(() => String, { description: 'メールアドレス', }) email: string; @Field(() => Int, { description: '年齢', }) age: number; @Field(() => [Post], { description: 'ユーザーの投稿', }) posts: Post[]; } @Resolver(() => User) export class UserResolver { constructor(private readonly userService: UserService, private readonly dataloader: PostDataloader) { } @Query(() => User) async user(@Args('id') id: string): Promise<User> { return this.userService.findById(id); } @ResolveField(() => [Post]) async posts( @Parent() user: User, ): Promise<Post[]> { return this.dataloader.load(user.id); } }
Dataloaderそのものの紹介や機能についてはここでは割愛しますが1つ注意点があります。それは、必ずキーの順序通りにレスポンスを返すということです。eScanチームでは、graphql/dataloader パッケージを利用しており、そちらのドキュメントにもサンプルコードと注意点が記載されていますので簡単にご紹介します。
There are a few constraints this function must uphold:
- The Array of values must be the same length as the Array of keys.
- Each index in the Array of values must correspond to the same index in the Array of keys.
https://github.com/graphql/dataloader?tab=readme-ov-file#batch-function
例えば、以下のようにキーの順序と結果のセットが保証されないような実装になっており、
async function batchFunction(keys) { const results = await db.fetchAllKeys(keys); return keys.map(key => results[key]); } const loader = new DataLoader(batchFunction);
keys: [2, 9, 6, 1]に対して戻り値が以下のような場合は、id: 6の結果がid: 1の結果として返ってしまうかつ、id: 1 の結果はないものと処理されてしまいます。
{
id: 9,
name: 'Chicago'
}
{
id: 1,
name: 'New York'
}
{
id: 2,
name: 'San Francisco'
}
async function batchFunction(keys) { const results = await db.fetchAllKeys(keys); return keys.map(key => results[key]); } const loader = new DataLoader(batchFunction); // 例) 関数の実行結果がキーの順序と一致しない // key(id:2) -> { id: 2, name: 'San Francisco' } // key(id:9) -> { id: 9, name: 'Chicago' } // key(id:6) -> { id: 1, name: 'New York' } 誤ったマッピング // key(id:1) -> undefined
今回のケースは、以下のようにキーの順序と結果のセットが保証されるように実装する必要があります。
async function batchFunction(keys) { const results = await db.fetchAllKeys(keys); return keys.map(key => results[key] || new Error(`No result for ${key}`)); } const loader = new DataLoader(batchFunction); // 例) 関数の実行結果がキーの順序と一致する // key(id:2) -> { id: 2, name: 'San Francisco' } // key(id:9) -> { id: 9, name: 'Chicago' } // key(id:6) -> Error // key(id:1) -> { id: 1, name: 'New York' }
エラーハンドリングの工夫
エラーハンドリングはGraphQLを運用する上で難しい課題の1つだと思います。eScanチームのGraphQL導入当初は、spec-Errorsに定義されている形でレスポンスを返していました。
フロントエンドではレスポンスをパースし、messageとextensionsに含まれるcode、APIごとの独自のプロパティをもとにユーザーへのフィードバックをハンドリングしていました。
{ "errors": [ { "message": "エラーメッセージ", "locations": [ //... ], "path": [ "user" ], "extensions": { "code": "BAD_REQUEST", // 固有のプロパティを追加する場合 "REASON_CODES": [ "INVALID_EMAIL", "INVALID_NAME" ] } } ], "data": { "user": null } }
しかし、このextensionプロパティは以下の型定義になっているため、型の補完には限界がありました。
export interface GraphQLErrorExtensions { [attributeName: string]: unknown; }
そこでeScanチームでは、HTTP Status Codeの4XXに該当するエラーはエラー用のスキーマを定義し、Resolverがそのエラーを返すように変更しました。これにより、フロントエンド側で想定されるエラーについてはスキーマから情報を取得できるため型付けが可能になり、適切なエラーハンドリングができるだけでなく型の補完も可能になるため開発がスムーズになりました。
@ObjectType() export class InvalidInputError { @Field(() => String) field: string; @Field(() => String) reason: string; } @ObjectType() export class UserInputError { @Field(() => String) message: string; @Field(() => [InvalidInputError]) errors: InvalidInputError[]; } const UserResult = createUnionType({ name: 'UserResult', types: () => [User, UserInputError], }) @Resolver(() => User) export class UserResolver { @Mutation(() => UserResult) async createUser(@Args('input') input: CreateUserInput): Promise<UserResult> { const errors: InvalidInputError[] = []; if (!input.email) { errors.push({ field: 'email', reason: 'メールアドレスが入力されていません', }); } if (!input.name) { errors.push({ field: 'name', reason: '名前が入力されていません', }); } if (erros.length > 0) { return { message: 'ユーザーが見つかりませんでした', errors, } } return this.userService.createUser(input); } }
実際にフロントエンド側では、以下のようなクエリを発行しエラーオブジェクトも取得するようにしています。バックエンド側がエラーを返却したかどうかは__typenameで判別し、エラーハンドリングを行っています。
mutation { createUser(input: { name: "", email: "", age: 20 }) { ... on User { __typename id name email age } ... on UserInputError { __typename message errors { field reason } } } }
一方で、5XXに該当するエラーが発生する可能性は残っていますが、以前と同じSpec通りのエラーを返すようにしています。実際に5XX系のエラーも4XX系と同等の対応をしようと思うと、想定されうるエラーをすべてスキーマに登録する必要がありますが、現実的ではありません。フロントエンド側もすべてのエラーがスキーマに登録されるとエラーハンドリングが煩雑になります。エラーハンドリングは、特に4XX系のユーザー起因のエラーにフォーカスし、5XX系のサーバー起因のエラーはある程度まとめてハンドリングするのがよいと考え、この方針で進めることにしました。
モニタリングの工夫
GraphQLのモニタリングもGraphQLを運用する上で難しい問題の1つです。具体的には以下のような問題があります。
- エンドポイントが1つであるため、Resolverごとのパフォーマンスを把握しにくい
- レスポンスのステータスコードがすべて200になってしまう
eScanチームでは以下のようにResolverに定義されているQueryやMutationのレイテンシーやHTTP Status Codeに相当する情報は、NestJSのinterceptor機能を使いログとして出力しています。
@Injectable() export class AccessLogInterceptor implements NestInterceptor { constructor( @Inject(AppLogger) private readonly logger: AppLogger, @Inject(AsyncStorageService) private readonly asyncStorageService: AsyncStorageService, ) { } intercept(context: ExecutionContext, next: CallHandler): Observable<unknown> { const now = Date.now() if (context.getType<GqlContextType>() === 'graphql') { // GraphQLリクエストの場合 const gqlCtx = GqlExecutionContext.create(context) const req = gqlCtx.getContext().req const info = gqlCtx.getInfo() const {path, variableValues, fieldName, schema} = info const {key, typename} = path const {params} = gqlCtx.getContext().req // 実際にはこの他ユーザーIDなども出力しています this.asyncStorageService.enterWith( new Map( Object.entries({ query: key, typename, params, }), ), ) this.logger.log(`GraphQL Query Start: ${key}`) return next.handle().pipe( tap({ next: () => { const latency = Date.now() - now this.logger.log(`GraphQL Query End - ${latency}ms`, { latency, status: 200 }) }, error: (error) => { const latency = Date.now() - now if (error.status < 500) { this.logger.warn( `GraphQL Query Warning - ${Date.now() - now}ms`, { latency, status: error.status, } ) this.logger.error( error.stack, `GraphQL Query Error - ${Date.now() - now}ms`, { latency, status: error.status, } ) } } }), ) } else { return next.handle() } } }
その他、リクエスト単位で永続したい情報がある場合は、Node.jsにあるAsyncLocalStorageをラップした AsyncStorageService を使用し永続化しています。
実際には、以下のようなクエリの詳細やレイテンシーなどの情報をDatadogで確認できます。
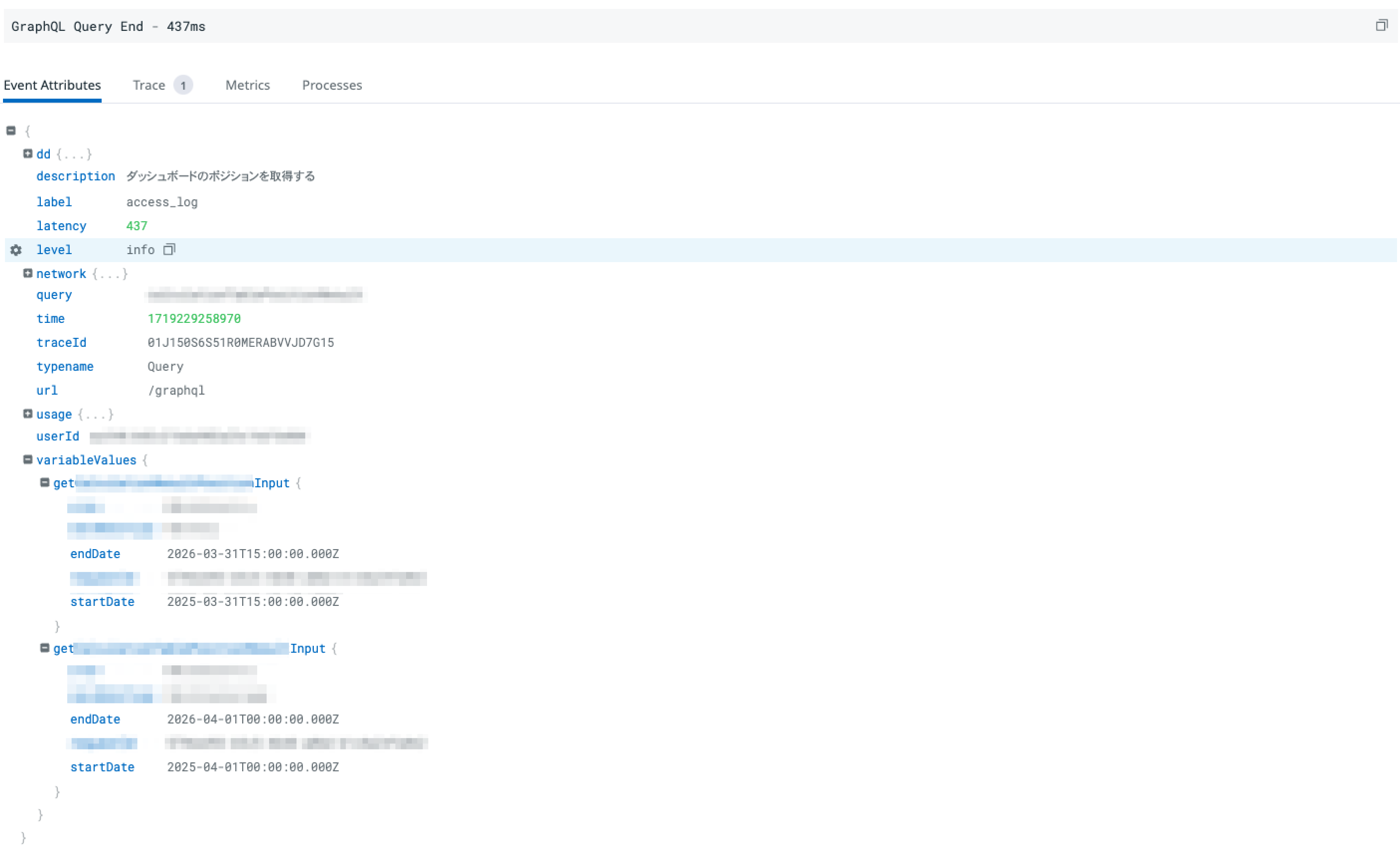
※ eScanチームで取り組んでいるGraphQLとDatadogのモニタリングについては、以下の記事を参照してください
ドキュメンテーションを必須化するための工夫
ResolverのQueryやMutationにはdescriptionを必ず定義し、descriptionを見るだけでQueryやMutationでどんなユースケースが体現されるか明確となるようにしています。descriptionの記載があると開発時にQueryやMutationの責務がより明確になったり、分析用の行動ログと紐づけることでエンジニア以外が見たときに理解しやすくなるというメリットもあるためこの取り組みを行っています。
eScanチームでは、このdescriptionを強制させるためにESLintプラグインを実装し、記入漏れがある場合はCIが失敗するようにしています。
const requireResolverDescription = { defaultOptions: [], meta: { type: 'problem', docs: { description: 'Require a description for @Query and @Mutation annotations', recommended: 'strict', }, messages, schema: [], }, create: function (context) { return { CallExpression: function (node) { if (!context.filename.endsWith('resolver.ts')) { return } // Check if the CallExpression is @Query or @Mutation if ( node.callee.type === 'Identifier' && (node.callee.name === 'Query' || node.callee.name === 'Mutation') ) { // Check if the second argument is an object with a 'description' property let description if ( node.arguments[1] && node.arguments[1].type === 'ObjectExpression' ) { const prop = node.arguments[1].properties.find( (property) => property.type === 'Property' && property.key.type === 'Identifier' && property.key.name === 'description', ) if ( prop?.type === 'Property' && prop.value.type === 'Literal' && typeof prop.value.value === 'string' ) { description = prop.value.value } } if (!description) { context.report({ node, messageId: 'descriptionMissing', }) return } } }, } }, }
その他の取り組み
上記でご紹介したもの以外に、以下ような対応も行っていますので簡単にご紹介します。
- Introspectionの無効化
- スタックトレースの非表示化
Introspectionは有効にしているとスキーマ情報を取得することが可能となります。開発用途では嬉しい機能ですが、プロダクション環境でスキーマ情報が取得できてしまうと、不正なクエリの発行につながってしまうためプロダクション環境では無効としています。
GraphQLのエラーレスポンスにはスタックトレースが含まれており、不正な情報を取得されるリスクがあるため、スタックトレースは非表示にしています。
ApolloServerであれば、includeStacktraceInErrorResponsesで設定でき、NODE_ENVがproductionまたはtestでない限りはtrueとなっています。心配であれば常にfalseにしておくとよいでしょう。
振り返り
2年間ほどGraphQLを採用したプロダクトを開発してきましたので、良かった点や難しかった点、今後の課題について振り返ります。
良かった点
GraphQLを採用して良かった点は以下の通りです。
- 何でも取ってくるようなAPIが生まれづらい
- 無駄な実装が減らせる
実際のAPI開発は、APIに対してリソースを追加していくというよりも互いのリソースに関連がある場合はリソースの関連を増やしていく。という形が多くなっています。関連を増やすだけであれば、ResolveFieldの追加と、必要であればDataloaderに対応するだけで済むため、なんでも取ってくるようなAPIは生まれづらくかつ、無駄な実装も減らせていると感じています。また、似たようなコードが散らばったり、無理のある共通化・抽象化も行われないため、比較的シンプルな設計・実装にできている点も良かったと感じています。
難しかった点
GraphQLを採用して難しかった点は以下の通りです。
- モニタリングに必要な情報を取得するための工夫
- エラーハンドリングに対するベストプラクティスの模索
モニタリングは筆者の調査不足もありますが、Datadogを導入した時点である程度プリセットにより基本的なメトリクスが取得できると思っていました。しかし、蓋を開けてみると必要な情報が全く取れていないという状態だったため、必要なものを精査し、取れていないメトリクスをどうやってDatadogに連携するか試行錯誤することが多かったです。
エラーハンドリングはSpecを参照しプラクティスに沿った開発を進められていると思っていました。しかし、補完が効かなかったり、実行時に型が合わないことによる意図しないアラートが発生したりと、開発体験の悪化や運用コストの増加という問題が発生したため、再度エラーハンドリングについて調査・検証し、今の形にたどり着きました。
現状細かい改善点はありますが、大きな課題は見つかっていないため、変更の必要性がない間は細かな改善をメインに運用をしていく予定です。
今後の展望
現状の運用で大きな問題は発生していませんが、よりセキュリティを向上させる、効率よくリソースにアクセスするという観点で、Persisted Queryは導入を検討すべき項目だと考えています。
Persisted Queriesは、クエリをハッシュ化してサーバーもしくはその前段となる場所で、クエリから送られてきたhashとクエリを交換して、あらかじめ登録されているクエリのみの実行を許可する仕組みです。
これにより、クエリ送信時にクエリを丸ごと送る必要がなくなるためクエリのサイズ削減ができ、あらかじめ登録されていないクエリは実行できないため、セキュリティリスク低減に繋がります。 また、Apolloのようなライブラリを用いることでAPIリクエストがGETで行われるようになるため、ブラウザキャッシュやCDNが活用でき、リクエストの高速化にも繋がります。
Automatic persisted queries - APOLLO
eScanチームでもGraphQL導入当初はPersisted Queryを検討していましたが、以下の理由によりセキュリティリスクはそこまで高くないと考え、導入を見送りました。
- クエリサイズが急激に増えることは想定されないこと
- クエリは認証後のみ実行可能という制約があること
しかし、現在は会社の規模拡大やeScanの導入企業増加などでフェーズが変わってきており、セキュリティリスクは高まっていると考えています。依然として、PublicなAPIを提供する予定はありませんが意図しないクエリが発行されるリスクはゼロではないため、今後は導入を検討していきたいと考えています。
最後に
今回はバックエンド視点でGraphQLを採用したプロダクト開発について振り返りました。GraphQLを採用したプロダクトを開発してから2年が経過しましたが、GraphQLのメリットは感じつつもREST APIに比べ特に運用面で対応しなければならないことが多かったです。本記事が、GraphQLの採用を検討している方やすでに開発・運用している方の参考になれば幸いです。
enechainでは、一緒に事業・組織を盛り上げていただける方を募集しています。
もしご興味持っていただけましたら、ぜひ一度カジュアルにお話してみませんか?以下のフォームより申し込みいただけます。お待ちしております!
オープンポジション