こんにちは、enechain でソフトウェアエンジニアをしている小沢です。
enechain では eSquare をはじめとした複数のプロダクトを運営しており、私は eScan という電力会社向けのリスクマネジメントシステム(ETRM: Energy Trading Management System)の開発・運用を担当しております。このプロダクトの技術スタックにはNestJS・GraphQL、モニタリングにはDatadogを使用しております。
※ eScan について知りたい方は以下の記事を参照してください。
techblog.enechain.com enechain.co.jp
今回の記事では、NestJSとGraphQLを使用したアプリケーションでモニタリングを始めるためにどのようなことを行う必要があるか、についてお伝えします。
プロダクト構成
eScanはフロントエンドもバックエンドもTypeScriptを共通言語として扱うようにしており、フロントエンドはReactを中心としたUI・ステート管理の技術スタックを採用しています。バックエンドはNestJSをWebアプリケーションの基本フレームワークとし、ORMにPrismaを採用しています。API通信にはGraphQLを採用しており、このスキーマをベースに型定義を生成し開発を進めていくようにしています。

Datadogとは
Datadogはクラウドネイティブなモニタリングサービスで、アプリケーションのログやメトリクス、トレースなどを収集し、可視化することができます。また、アラートを設定することで、アプリケーションの障害を検知することもできます。
eScanではAPM(Application Performance Monitoring)機能を使用して、バックエンドのパフォーマンスをモニタリングしています。APMを活用することで、GraphQLクエリが実行されてからレスポンスが返るまでにどんな処理が呼ばれて何が起きているのか確認することができ、問題が発生したときの原因特定に役立ちます。
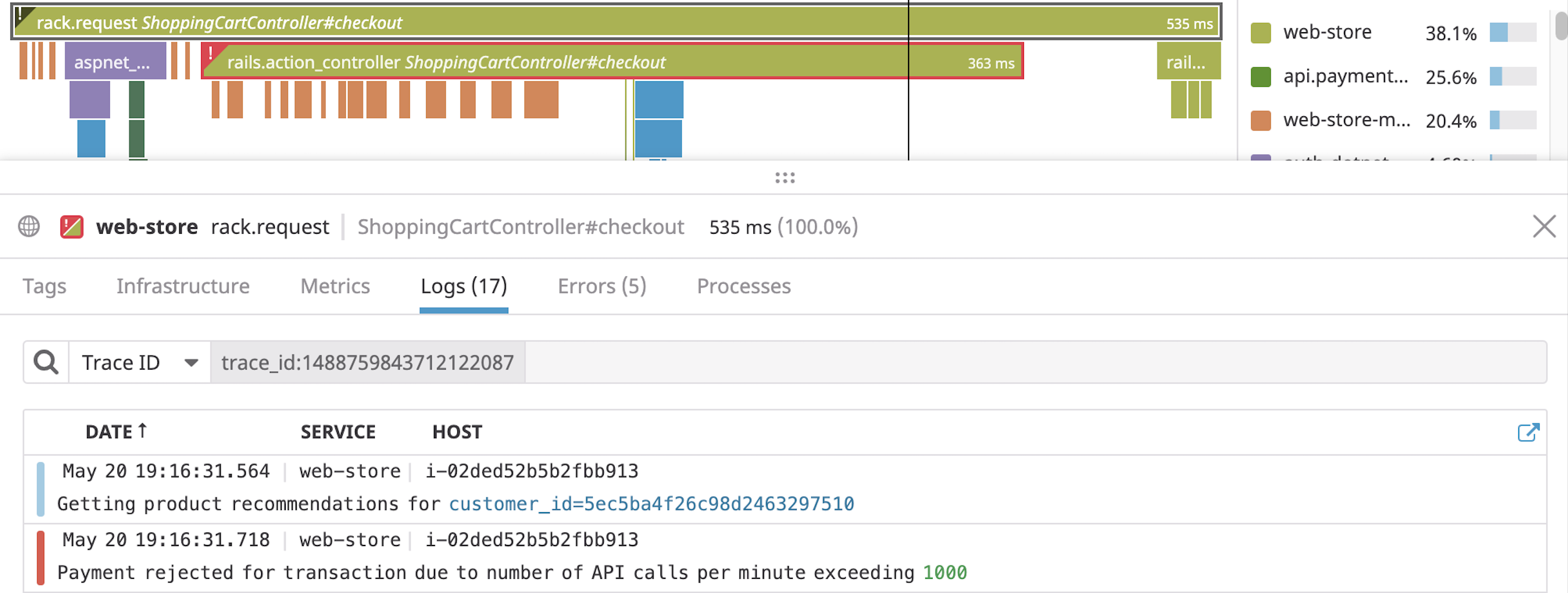
APMとは
APMは、Webサービスがリクエストを処理するために必要な構成要素(データベースやキューイングシステムなど)とその処理結果の監視を行う機能です。その結果をダッシュボードに可視化することで、Webサービスがリクエストを受け付けてから処理を完了するまでに、何が呼ばれどのくらい時間がかかっているか知ることができます。
この可視化には分散型トレースという仕組みを利用しています。ここではDatadogで使われる用語の説明だけ行い、分散型トレースについての説明は割愛させていただきます。
| 用語 | 説明 |
|---|---|
| Trace(トレース) | アプリケーションがリクエストを処理するのにかかった時間とこのリクエストのステータスを追跡するために使用されます。各トレースは、1 つ以上のスパンで構成されます。 |
| Span(スパン) | 特定の期間における分散システムの論理的な作業単位です。複数のスパンでトレースが構成されます。 |
用語集から抜粋
GraphQLを扱うプロダクトにおけるDatadogモニタリングの課題
Datadogをプロダクトに導入しログの収集やAPMの可視化は比較的に簡単にできますが、NestJS+GraphQLの環境下におけるDatadogモニタリングの最大の課題は、「デフォルト設定で取得出来る情報が極めて限定的」という課題です。
特に以下2つの課題を解決しなければ、障害対応やパフォーマンス改善などの課題を解決することが難しくなります。
- 課題1: GraphQLのクエリ情報(クエリ名やパラメータなど)が取得できない
- 課題2: リクエスト以降に呼び出された関数や処理時間が取得出来ない
初期設定状態を確認する
実際に以下の初期設定と最低限のプラグインの設定を行い、トレース情報を取得してみます。
- datadog-trace
- expressのプラグインを有効にする
- graphqlのプラグインを有効にする
import {tracer} from './tracer' tracer .init({ plugins: true, }) .use('graphql', { // GraphQLプラグインの有効化 measured: true, enabled: true, source: true, // クエリ全体がわかるので設定しておくのが良い }) .use('express', { // Expressプラグインの有効化 measured: true, enabled: true, middleware: true, }) export default tracer
この状態アプリケーションを起動し任意のクエリを発行します。設定内容が正しければ下図のようなグラフと詳細情報が見ることができます。しかし、障害対応やパフォーマンス改善などを想定すると情報が不十分であることがわかります。
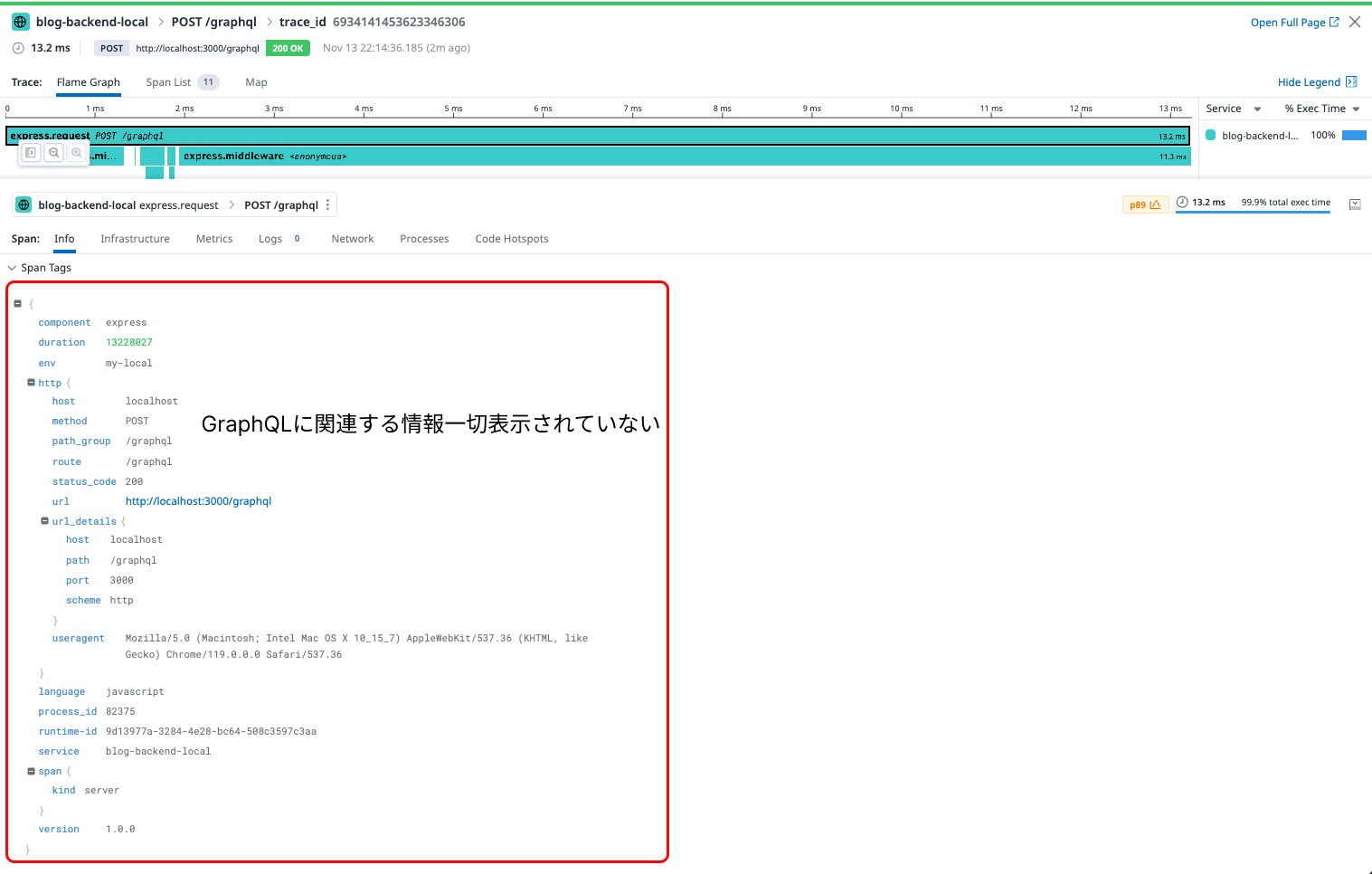
課題1: GraphQLのクエリ情報(クエリ名やパラメータなど)が取得できない問題
APMに連携される一番最初のスパンがエンドポイントへアクセスしたときの情報です。このとき以下値を取得できますが、先程見た初期設定時の画像の通りGraphQLのクエリ情報は取得できておりません。
- ホスト
- URL
- ユーザーエージェント など
その他にトレース一覧画面を見てもGraphQLに関する情報が取得できていないため有効な絞り込みが行えません。

課題2: リクエスト以降に呼び出された関数や処理時間
エンドポイントへアクセスしたときの情報は取得できますが、それ以降でどんな関数が呼ばれたか、その関数実行にはどのくらい時間がかかったといった情報は取得できません。そのため、エンドポイントの処理時間に問題があったとしても具体的にどこに時間がかかっているかは自前でログを挿入するなどして取得する必要があります。この場合は問題が発覚してからログを追加する形になるので、発生タイミングで必要な情報にアクセスできません。
GraphQLを扱うプロダクトにおけるDatadogモニタリングの解決策
上記課題を解決するために以下のような手順で設定を追加していきます。ORMにPrismaを使用していない場合はStep4は不要です。
- Step1: GraphQLのクエリ情報を取得しスパンに設定する
- Step2: ユーザー情報を取得しスパンに設定する
- Step3: 任意の関数にトレース設定を追加する
- Step4. Prismaのクエリを発行する関数にトレース設定を追加する
Step1: GraphQLのクエリ情報を取得しスパンに設定する
Datadogライブラリのプラグインにgraphqlに対する設定は存在しますが、一番最初のスパンでGraphQLに対する情報は取得できないためexpressプラグインのhookを利用して、GraphQLのクエリ情報を取得するようにします。その後、その取得した内容をタグとしてスパンに設定します。
具体的には、expressのhooksのrequestにはエンドポイントへアクセスしたときの情報が含まれているためそこから情報を取得します。ただし、payloadの内容はGraphQLの構文として解釈しないとクエリ名や種別といった情報が取得できないのでパースして取得します。
// gql-query.ts import { z } from 'zod' // zodを使って最低限の型を保証する const queryRequestSchema = z.object({ body: z.object({ query: z.string().min(1), }), url: z.string().min(1), method: z.enum(['POST', 'GET', 'OPTIONS', 'PUT', 'DELETE', 'PATCH']), originalUrl: z.string().min(1), }) const parseRequest = (req: unknown) => queryRequestSchema.safeParse(req) export const extractQuery = (req: unknown) => { const result = parseRequest(req) if (result.success) { return result.data.body.query } return undefined } export const isGraphQLRequest = (req: unknown) => { const result = parseRequest(req) if (result.success) { const { url, method, originalUrl } = result.data return url === '/' && method === 'POST' && originalUrl === '/graphql' } return false } // tracer.ts import {tracer} from './tracer' import { parse } from 'graphql' tracer .use('express', { // Expressプラグインの有効化 measured: true, enabled: true, middleware: true, hooks: { request: (span, req) => { if (isGraphQLRequest(req)) { const documentNode = parse(String(extractQuery(req))) let operationName = '' let operationPattern = '' // ドキュメントへアクセスし、Operation情報を拾う for (const node of documentNode.definitions) { if (node.kind === 'OperationDefinition') { operationName = node.name?.value ?? '' operationPattern = node.operation } } span?.setTag('operationName', operationName) // タグにクエリ名を設定 span?.setTag('operationPattern', operationPattern) // タグにクエリの種別を設定 } }, }, }) export default tracer
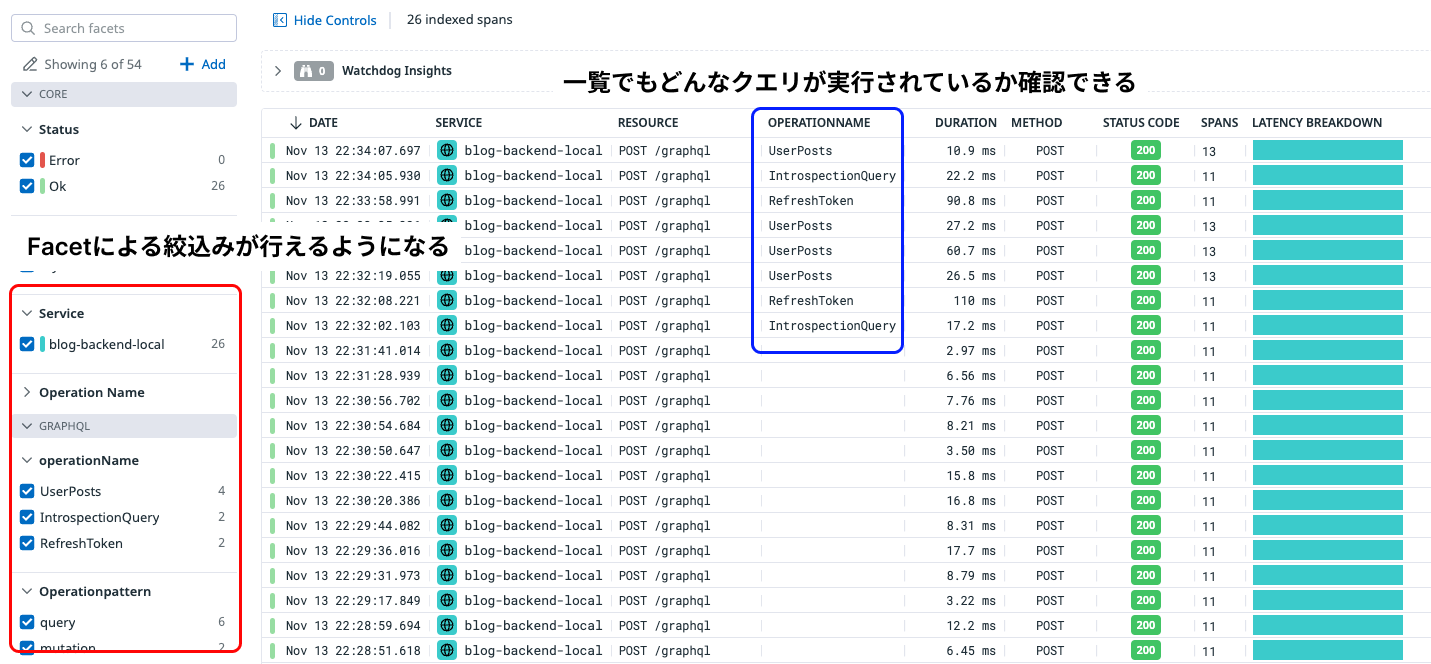
ここでクエリ名や種別、必要に応じてパラメータなどを取得しタグとして設定します。そうすることで受け付けたリクエストのクエリがなにか、パラメータがなにかという情報を知ることができるようになります。
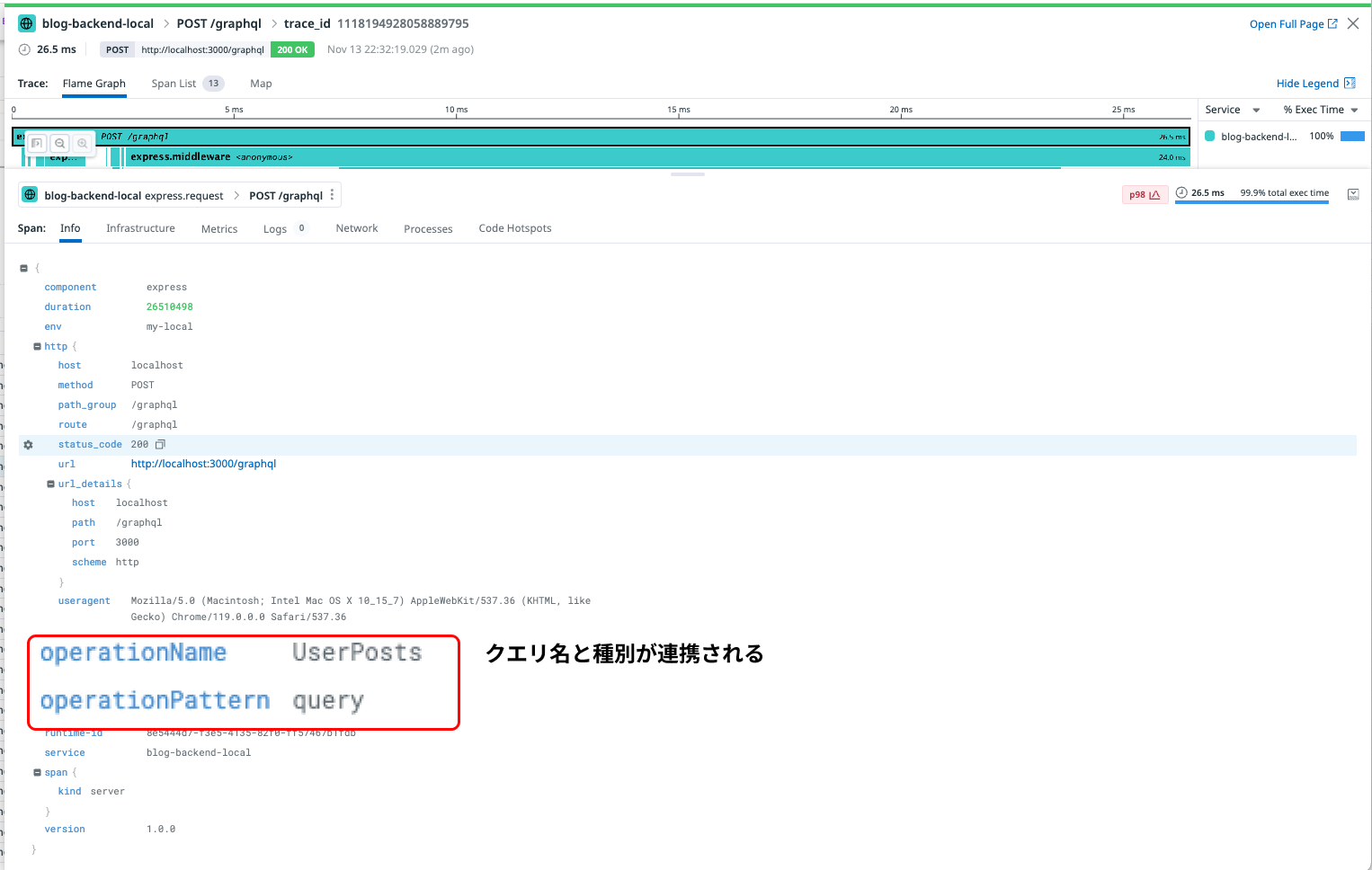
また、ここの情報はトレース一覧画面での絞り込みにも有効になるため、クエリやクエリの種別による絞り込みっといったことができるようになります。
Step2: ユーザー情報を取得しスパンに設定する
GraphQLだけの情報だけでなくユーザー情報も連携しておくと、障害対応などに役立つので最初から設定しておくことをおすすめします。ユーザー情報もリクエストに含まれるので、その情報を取得しタグにユーザー情報を設定しています。
tracer .use('express', { measured: true, enabled: true, middleware: true, source: true, hooks: { request: (span, req) => { if (isGraphQLRequest(req)) { const documentNode = parse(String(extractQuery(req))) let operationName = '' let operationPattern = '' for (const node of documentNode.definitions) { if (node.kind === 'OperationDefinition') { operationName = node.name?.value ?? '' operationPattern = node.operation } } const {userId} = extractUserInfo(req) // tracer.setUserで設定しても良い span?.setTag('operationName', operationName) span?.setTag('operationPattern', operationPattern) span?.setTag('userId', userId) } }, }, })
Step3: 任意の関数にトレース設定を追加する
GraphQLのクエリ情報を取得することができたので、次はリクエスト以降に呼び出された関数や処理時間を取得するようにします。Datadogライブラリには自動で関数ごとのスパンを取得する機能がないため、以下のようにtrace関数を呼び出し、その中で計測したいコードを実装します。
以下例ではトレースの実装を少し楽にするラッパー関数を作っています。
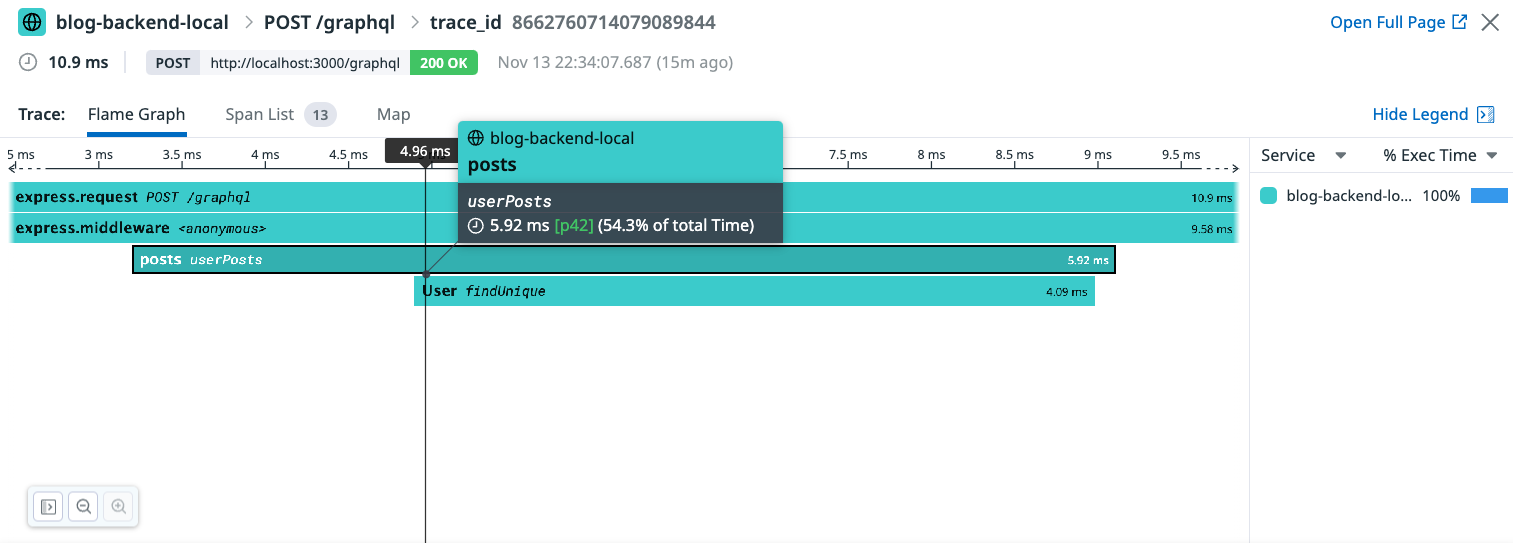
// datadog-lib.ts import { tracer } from 'dd-trace' export const withTrace = (that: any, resourceName = 'execute') => (fn: (...args: any[]) => any) => { return tracer.trace( that.constructor.name, { resource: resourceName, }, fn, ) } // user-resolver.ts @Query(() => [Post]) userPosts(@Args() id: UserIdArgs) { return withTrace(this,{ resource: 'userPosts' })(async () => { return this.prisma.user .findUnique({ where: { id: id.userId } }) .posts({ where: { published: true } }); }); }
これを主要な関数、例えば、プレゼンテーション層・アプリケーションサービス層(またはユースケース層)・ドメイン層・インフラ層といったところに設定するとこの一連の処理と各処理の情報を取得できます。
Step4. Prismaのクエリを発行する関数にトレース設定を追加する
ORMにPrismaを利用している場合は5系から使用できるPrisma Client Extensionを活用すると全クエリの情報を取得することができます。
prisma.$extends({ query: { $allModels: { $allOperations({ query, operation, model, args }) { return tracer.trace( `${model}`, { resource: `${operation}`, }, async (span) => { span.setTag('component', 'prisma'); return query(args); }, ); }, }, }, });
修正後のAPMを見てみる
今までの設定をすべて行うと以下のようなトレースやスパンを取得することができます。
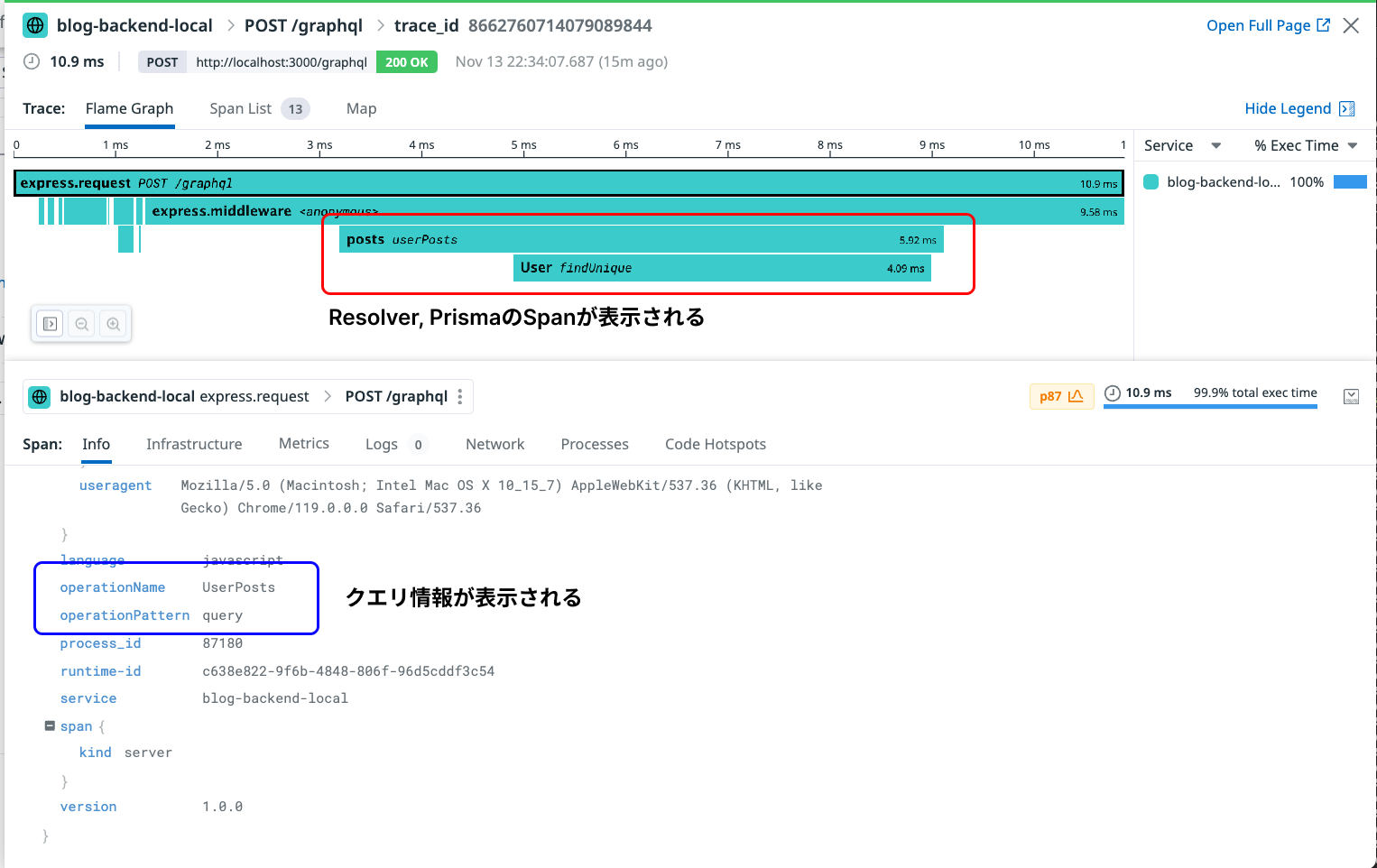
修正前はexpressとgraphqlの一部の情報しか取得できませんでしたが、エンドポイントからDBアクセスまでの一連の流れがどのようになっているか把握できるようになりました。これであれば障害発生時やパフォーマンス改善で誰がどのクエリを実行して問題が発生したか把握することができます。
今後の展望
今回はNestJSとGraphQLの情報をAPMに連携する方法を記載しましたが、まだ以下のような課題があります。
- 一部の情報しか連携が自動化されていない
- クエリの実行結果(HTTPステータスコード相当の情報)が連携できていない
特に前者の問題については、今はエンドポイントのトレースとPrisma部分は自動的に連携されるようになりましたが、リゾルバーへのアクセス以降の各レイヤーのトレース情報は自動で連携されるようにはなっていません。トレースは全機能取得しておくことが理想ですので、新規開発の際は何も設定せずとも自動で取得できる状態が覗かしいです。今後はAOP的なアプローチでDIされるすべてのクラスおよび関数にtracer.traceでラッパーするような仕組みを作ったり、Prismaのトレース情報も統合できるようにOpenTelemetryを使った連携方法に移行するなどの改善を行っていきたいと考えています。
まとめ
今回はNestJSとGraphQLを使用したアプリケーションでDatadogのモニタリングを始めるためにどのようなことを行う必要があるか、についてお伝えしました。まずは最低限の設定を行い、モニタリングをできる状態にするのが大切だと思います。これ以降はプロダクトの特定に合わせて様々な情報をAPMに連携していくのがよいでしょう。最後に、NestJSとGraphQLをDatadogでモニタリングする部分については情報が少なく試行錯誤しながら進めました。その内容を記事にすることでモニタリングをするきっかけや参考になれば幸いです。
enechain では、事業拡大のために共に技術力で道を切り拓いていく仲間を募集しています。