
はじめに
enechain データプラットフォームデスク エンジニアの鳥山です。
enechainが運用する複数のプロダクトは、それぞれGoogle Cloud Platform(GCP)上で独立したプロジェクトとして構築されています。本稿ではそれらのプロダクトのログを横断的に収集管理する仕組みについて紹介します。
背景
アプリケーションにおいてログ管理の重要性は言うまでもありません。維持運用の観点では障害調査やインシデント発生時の証跡保全、また一般的なビジネスの観点でもデータドリブンな意志決定のためにログは重要な役割を果たします。
加えて、enechain特有のビジネス要件から考えてもログ管理は重要です。enechainの運営する電力のオンライントレーディングプラットフォームeSquareは大手の電力会社様にもご利用いただいておりますが、特に旧一般電気事業者(電力自由化前から地域ごとに存在する大手電力会社)の電力卸取引には公平性が求められます。プロダクトユーザーの利用ログを保管・参照できる仕組みはそれら取引が公平に行われていることの証拠として公的機関から高く評価されています。
共通ログ基盤を設ける利点
前述のeSquareの他にも、電力関連のマーケットインテリジェンスを提供するeCompass、電力ポートフォリオのリスクマネジメントをサポートするeScanなどenechainは複数のプロダクトを提供しています。それらのサブシステムを含めると非常に多くのGCPプロジェクトが存在し、そこから日々発生するログは膨大なものとなります。これらのログ管理を各プロダクトで個別に設計することは非効率であることに加え、長期的にはデータがサイロ化し、プロダクト間でログが分断して横断的な分析がやりにくくなる懸念もあります。
共通的なログ基盤の構築はこれらの問題を解決することに加え、データに対するアクセス権限の制御やアプリケーションの異常検知の仕組みを一元管理することも容易にします。
全体像
enechainが採用する共通ログ基盤の全体像は以下のようなイメージです。
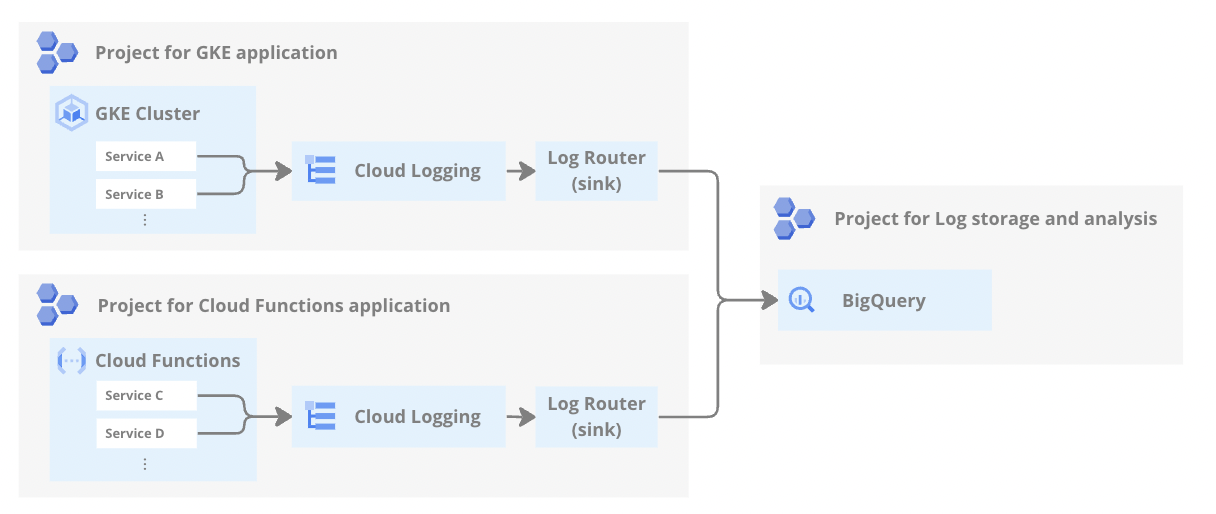
GCPではアプリケーションやその他コンポーネントのログはCloud Loggingに転送されるのが一般的です。Cloud Loggingに送られたログを他のプロジェクトやストレージ等に再転送するログルーターという仕組みを用いて、Cloud Logging経由で複数のプロジェクトのログを1つのプロジェクトに集約しています。
この方式を取ることで、共通基盤へのログ集約について各アプリケーション側から意識することを少なくできます。詳細は次項で述べますが、アプリケーション側はログの出力形式だけに注意すればよく、出力されたログをどのように転送・集約するかはアプリケーションの外側で管理することができるからです。
ログルーターを用いた実装
今回の基盤設計上のコアサービスであるログルーターについて、具体的な実装方法をお見せしながら特徴を紹介します。ログルーターはGCPコンソールではCloud Loggingのメニューから参照することができます。
サンプルを作成してみます。シンクの作成を押した後は、指示に従うだけで簡単に完成します。

転送先には様々な選択肢があります。安価にログを永続化したいだけならCloud Storageバケット、ログの分析にも使用したいならBigQuery データセット、サードパーティー製品に対して連携したいならCloud Pub/Sub トピックが考えられます。enechainでは短期的なログ管理にDatadogを採用しており、連携手段の1つとして実際にこの機能を用いています。
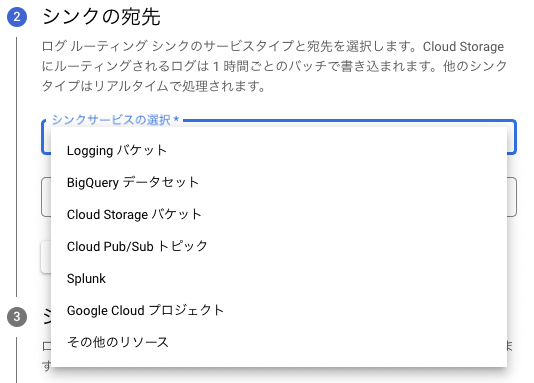
今回はサンプルのためにCloud Loggingと同じプロジェクト内のBigQueryを宛先にしていますが、ログを集約するという観点ではログ管理用のプロジェクトを別途用意し、そちらへの転送が適切です。プロジェクトを分割することでログに関する権限管理やコストの可視化が行いやすくなります。例えばCloud StorageバケットやBigQuery データセットを選んだ後に画面の指示に従うことで別プロジェクトに対する転送も容易に行うことができます。
最後に、転送する条件および除外条件を指定します。画面上でも注意が表示されますが、これを指定しないとCloud Loggingに送られる全てのログが転送対象となってしまいます。管理したいリソースやログレベルに基づいて設定しましょう。複数のシンクを作成することでログによって宛先を仕分けることもログ整理の観点で有効です。今回は簡単に、特定のCloud Functionsから出力されたJSON形式のログを対象とします。
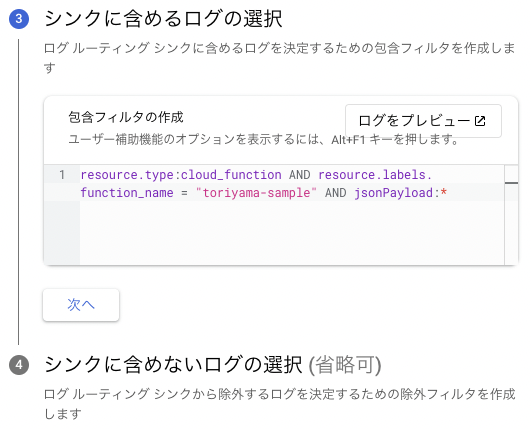
この設定書式はCloud Loggingでログをクエリする際の書式と共通であり、ログをプレビューを押すことで実際にCloud Loggingの画面でそのクエリの実行結果、すなわちこのシンクが転送対象とするログがどれになるかを確認することができます。転送したいログがどのような条件で抽出できるかわからない場合、Cloud Loggingで実際にログを確認しながらこの項目を設定すると効率的です。
シンクの作成が完了したら、実際に条件に合うログをCloud Loggingに出力してみます。
指定したデータセット以下にテーブルが作成されていれば成功です。BigQuery上にログを永続化、SQLで参照可能な状態にすることができました。

このとき、テーブルはCloud Logging上のログ名に応じて自動的に生成されます。生成されたテーブル構造はCloud Loggingの構造をそのまま表現してしまうため無駄なカラムも多くなり、そのままでは使いづらいケースもあるかもしれません。その場合、このテーブルを元にして分析用途に使いやすいようなデータマートに加工したり、ログ転送の段階でDataflow等のデータ整形を行う製品を経由してカラムを選別した上でテーブルに振り分けるなど、より使いやすく基盤を構築することも可能です。
プロダクトへの導入
共通ログ基盤の仕組みを構築後、新しいプロダクトにおいては基盤を利用する前提で設計構築することでログの保管に関して考えることが少なくなりました。
加えて既存プロダクトへの導入も進めています。スタートアップとしてスモールスタートを行う場合、このような共通的な仕組みが考えられる前に作成されてしまったプロダクトの扱いは課題です。enechainにおいてもこれは課題であり、共通ログ基盤の利活用に向けた共通ロガーの社内共有やログ基盤の利用方法・集められたデータの活用方法について勉強会を行うなどの方法で段階的に解決を図っています。
今後の展望
一箇所に集められたデータはSQLにより横断して参照可能になりましたが、前提としてSQLの知識が必要という課題は残ります。これについてはDataformやLooker Studioを活用したデータマート化・ダッシュボード化を行うことでデータ活用の敷居を下げ、ビジネス・プロダクト運用双方に対し利用を促進していく予定です。
また、今後のプロダクト構築において社内でアプリケーションボイラープレートを作成する計画が進んでいます。この中には共通ログ基盤をスムーズに利用できるような仕組みも組み入れることで、よりスムーズなプロダクト立ち上げ・デリバリースピードの向上を目指しています。
最後に
enechainのプロダクトとビジネスを支える共通ログ基盤についてご説明させていただきました。 今回は非常に初歩的な部分に留まりましたが、より高度なログ整理や利活用についても機会があればご説明させていただきます。