

概要
enechain では電力会社向けのリスクマネジメントシステム(ETRM: Energy Trading Management System)「eScan」を提供しています。eScan では日々複雑なリスク計算処理を実行し、電力会社のリスクを可視化することができます。この記事では高速化・安定化を目的に構築した BigQuery + Argo Workflows の計算処理基盤を紹介します。以前 Node.js で実装していた頃より従来比 25 倍以上の高速化を実現することができました。
※ eScan について知りたい方は以下の記事を参照してください。
なぜ BigQuery + Argo Workflows で計算基盤を構築したのか?
背景:Node.js を辞めた理由
eScan のリスク計算処理は Node.js で実装されていましたが、以下の理由から他の手段に乗り換える必要がありました。
- Node.js でデータを引き回しており、データ量の増加に伴いメモリ使用量が許容量を超えてしまった
- Node.js はシングルスレッドのため、計算ステップを並列で走らせるにはひと手間必要だった
- for ループのネストが深くなりすぎてコードの可読性が悪かった
そもそもそのような計算処理を Python ならまだしも Node.js で実装していたこと自体がナンセンスだという声もあるかもしれませんが、eScan の技術スタックがフロントエンド React、バックエンド NestJS というように Javascript エコシステムで実装されていたため、そのままアセットを利用して実装していました。
検討:BigQuery を選んだ理由
ロジックの移植先として、Spark のような分散処理フレームワークも検討しましたが、以下の理由から BigQuery を選びました。
- リソースの管理をクラウドに任せられ、並列実行が簡単
- for ループのネスト箇所を SQL の JOIN なら数行で済ませられる
- 中間テーブルを利用したワークフローにすれば途中の計算結果を簡単に参照できる
- 過去の計算の入力データや計算結果を一定期間残しておける
- 社内の共通 BigQuery から価格などのデータを PostgreSQL へのインポートする処理が不要になる
どれも重要な観点なのですが、エンジニア以外の PdM や数理モデルを作成するクオンツが SQL で簡単にデータを検証できるようになったのは、データ検証において大きな手助けになりました。
検討:Argo Workflows を選んだ理由
BigQuery を利用する際に同時に何でワークフロー制御させるかについて検討しました。正直 DAG が書けてリトライできるならばこだわりはなく、Airflow でも他のワークフローツールでも問題ありませんでした。
当初は Airflow の方が Operator との組み合わせで簡単に処理が書けそうと思っていたのですが、既に Argo Workflows を一部で利用しており複数のワークフローシステムを管理するデメリットを考え、Argo Workflows を採用しました。
BigQuery を利用するにあたって検証したこと
1. PostgreSQL から BigQuery へのデータ Sync 方法
リスク計算時には PostgreSQL にあるマスターデータを BigQuery にコピーする必要がありました。マスターデータは顧客が日々変更するため、計算時に最新のデータが BigQuery になければなりません。
コピー方法として以下の2つを検討しました。
- DataStream for BigQuery(CDC)
- EXTERNAL_QUERY
DataStream が用途にマッチすれば作業量やコード量を減らせるため、最初に技術検証をしました。PostgreSQL の Enum に対応していなかったり、データの結果整合性へ不安があったりといくつか懸念点はあったのですが、特にクリティカルな部分だったのは PostgreSQL へ直接 SSL 接続ができず、SSH トンネルか VM を使って接続をしなければならなかったため、残念ながら採用を諦めました。
DataStream の利用を諦めたため、最終的には EXTERNAL_QUERY を利用した実装方法にしました。EXTERNAL_QUERY を使うと BigQuery から直接 PostgreSQL にクエリを投げることができます。毎回大きなデータをコピーすると効率が悪いため、一部データは BigQuery に事前に置いておき、計算実行時には小さいデータだけをコピーするように工夫しました。
2. Javascript ライブラリの利用
eScan の計算処理では自由に計算式を設定することが可能です。その計算式をパースしてロジックに落とし込む処理はライブラリ化されており、Javascript で実装されています。ライブラリについての詳しい説明は以下の記事を参照してください。
このライブラリが BigQuery 上でちゃんと動くか、パフォーマンス的に問題がないかが一番の心配事でした。また動くようであれば今後複雑な処理が入ってもある程度は Javascript で吸収することができ、拡張性に期待ができます。
ライブラリは iife 形式 (Immediately Invoked Function Expression)でビルドし、その生成物を GCS 上に配置することで BigQuery から読み込むことができ、最終的には eScan での利用時には特に大きなつまづきはなく、実行することができました。
BigQuery + Argo Workflows を用いた計算基盤の全体像
計算基盤構築後のアーキテクチャは以下のような図になります。

現在では以下のようなワークフローが実際に並列で実行されています。
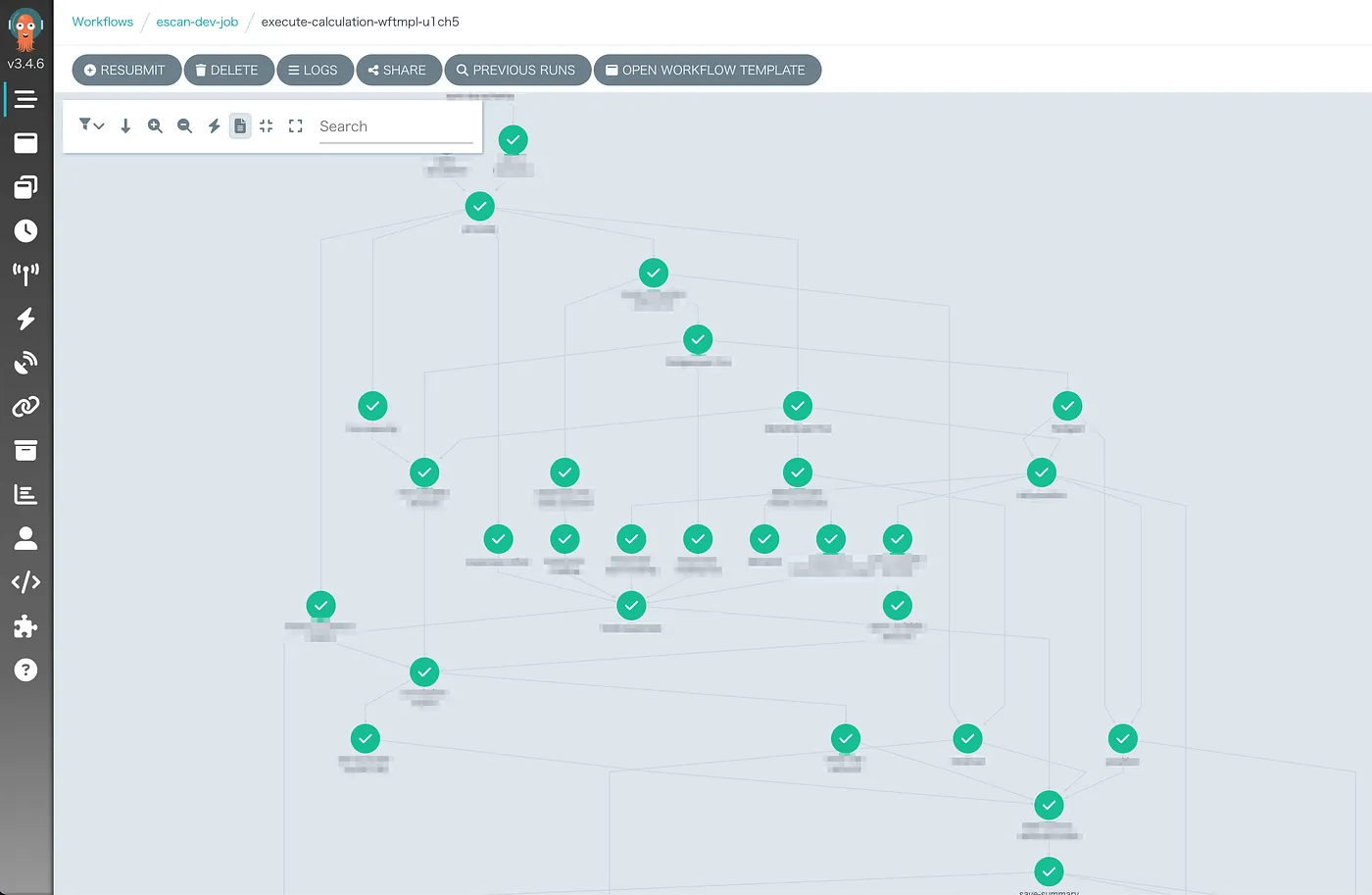
基盤構築後に、今まで数時間かかっていたリスク計算処理を実行したところ、なんと 25 倍以上の速度で完了することができました。Node.js の頃はデータ量が増えたときに線形に経過時間も増えていきましたが、BigQuery ではほとんど実行時間が変わらず安定した速度で実行できています。
また、重い処理を BigQuery 側に任せることで、アプリケーション側は BigQuery の状態を watch するだけになるため、Kubernetes の Pod のメモリ上限を他のサービス同様の数値に落とすことができ、Node が専有されるという問題も解消されました。
TIPS:計算基盤構築、計算ロジック移植時に得た教訓
ここから BigQuery と Argo Workflows で実装した際に苦労したことや得られた知見を説明します。
TIPS1:SQL では WITH 句の内容を繰り返し使わず、CREATE TEMP TABLE を利用する
長い SQL を書くときによく利用する WITH 句ですが、実際は名前付きのサブクエリでしかなく、複数回参照するとその回数分だけ計算されてしまいます。
-- WITH句の例 WITH a AS ( SELECT ... ) SELECT a.dim1 FROM a;
この点は CREATE TEMP TABLE を使うことで参照を 1 回に抑えることができます。さらに、CREATE TEMP TABLE を使うことで実行計画がとても見やすくなり、チューニングしなければならない箇所もわかりやすくなります。
-- TEMP TABLEの例 CREATE OR REPLACE TEMP TABLE a AS ( SELECT ... ); SELECT a.dim1 FROM a;
eScan ではどうしてもクエリ中で CROSS JOIN を利用しなければならない箇所があり、CROSS JOIN が WITH 句に入っていて処理が終わらないことがありましたが、TEMP TABLE に変更することで正常に実行が完了するようになりました。
TIPS2:JOIN の OR は避け、UNION ALL で代用する
JOIN 時に条件箇所に OR の指定があると処理時間が長くなってしまうという問題がありました。
-- 条件にORが入っている例 SELECT * FROM table1 LEFT JOIN table2 on (table1.id1 = table2.id3) or (table1.id2 = table2.id4)
OR を使うと絞り込みが大変になるので直感的にも遅くなるのはわかります。そんな場合は UNION ALL を使った書き方に変更すると速度が速くなることがあります。
SELECT * FROM table1 LEFT JOIN table2 ON id1 = id3 UNION ALL SELECT * FROM table1 LEFT JOIN table2 ON id2 = id4
SQL のシンプルさは失われますが、eScan ではボトルネックになっていた処理が 5 倍以上速くなりました。
TIPS1 も同様ですが、BigQuery は書き方次第で大きく実行時間が変わるため、一定のコーディングルールを作って運用していくと良さそうです。
TIPS3:ローカルのテスト環境では BigQuery Emulator が使えるが銀の弾丸ではない
結論から言うと、ローカルのテスト環境づくりに関してはまだ整備できていません。
当初は株式会社メルカリでも採用されている BigQuery Emulator を利用してローカルのテスト環境を構築しようとしました。
しかしながら、本番の BigQuery では動くが BigQuery Emulator では動かないということが複数回発生し、途中から BigQuery Emulator で動く SQL を書くにはどうしたらいいかと悩むようになってしまいました。
そのため全てをローカルでテストすることは諦め、BigQuery Emulator を使ったテストは一部のみにし、残りは GCP 上で動作確認をするようにしました。
ローカルで簡単に確認できないままにはしたくないですし、BigQuery Emulator の発想は素晴らしいので、洗練されていけば利用を拡大していきたいと考えており、弊社メンバーも気づいた点は Pull Request を送って改善をしていきたいと思います。
TIPS4:Workflow の podSpecPatch で DRY に
前提として、今回のケースでは Workflow の Job はほぼ2種類しかありません。
- BigQuery でクエリを実行し計算をする
- BigQuery から計算済みのデータを取得し PostgreSQL に保存する
Argo Workflows の Job 設定を書くときに template を用いてなるべく共通化していきたいところですが、この 2 つ Job は必要なメモリ量が異なります。1. の Job は BigQuery で完結するため少ないメモリ量で済みますが、2. の Job は大きいデータをメモリで展開する必要があるため、必要なメモリ量が増えます。
template の containers.resources には変数を指定することはできないため異なるメモリを設定する場合 template を複数書く必要がありますが、podSpecPatch を活用すると Pod の Spec を定義してメモリ量を変更できるので、DRY に YAML を書くことができます。
apiVersion: argoproj.io/v1alpha1 kind: WorkflowTemplate metadata: name: dynamic-resource spec: entrypoint: main serviceAccountName: argo-sa templates: - name: main dag: tasks: - name: single template: step arguments: parameters: - name: cpu value: "1000" - name: double template: step arguments: parameters: - name: cpu value: "2000" - name: step inputs: parameters: - name: cpu podSpecPatch: | containers: - name: main resources: limits: cpu: "{{inputs.parameters.cpu-limit}}" container: image: alpine:latest command: ["/bin/sh", "-c"] args: ['echo "step1"']
さいごに
enechain では、電力会社向けのリスクマネジメントシステム eScan のようなデータセントリックな技術的難易度の高いプロダクトがあり、エンジニアにとっても面白い環境だと思います。
また、eScan 以外にも、エネルギーやカーボンクレジットの取引所である「eSqaure」、エネルギーや電力市況を把握できる「eCompass」、など複数プロダクトを運営しています。こちらの記事を読んで、ご自身の成長と、弊社でのこれからエネルギー市場への貢献に関心を持ちましたら、ご応募していただけますと幸いです。
We are hiring!