
はじめに
enechainのデータプラットフォームデスクでエンジニアをしているakizhouです。
我々データプラットフォームデスクは業務の一部として、enechainが提供するeCompassと呼ばれる「エネルギー関連データ提供SaaS」で使用されるデータ収集および集計を行うデータパイプラインを開発運用しています。
以前の記事でも触れたように、このデータパイプラインは複数の課題を抱えており、現在はアーキテクチャから根本的再設計と移行を進めています。
今回は実際に決定したアーキテクチャとそれが解決する課題に関して、まだ移行途中ではありますが実行の基盤部分について紹介します。
そもそも何を移行しているのか
冒頭でも触れましたが、弊社にはeCompassというデータダッシュボードサービスがあります。 このサービスが提供するデータは主にETLパイプラインが外部からデータを収集したり処理しています。 またパイプラインにより処理されたデータはeCompass以外のサービスや社内の分析用として複数の利用先が存在します。
このパイプラインが扱うデータのフォーマットはテーブルデータのみで、現状データのパースと変換処理はすべてPythonで実装されており、実行はGoogle Cloud Functions上で行い、Pub/SubでCloud Functions間のトリガーを行うことによりパイプラインを構成しています。
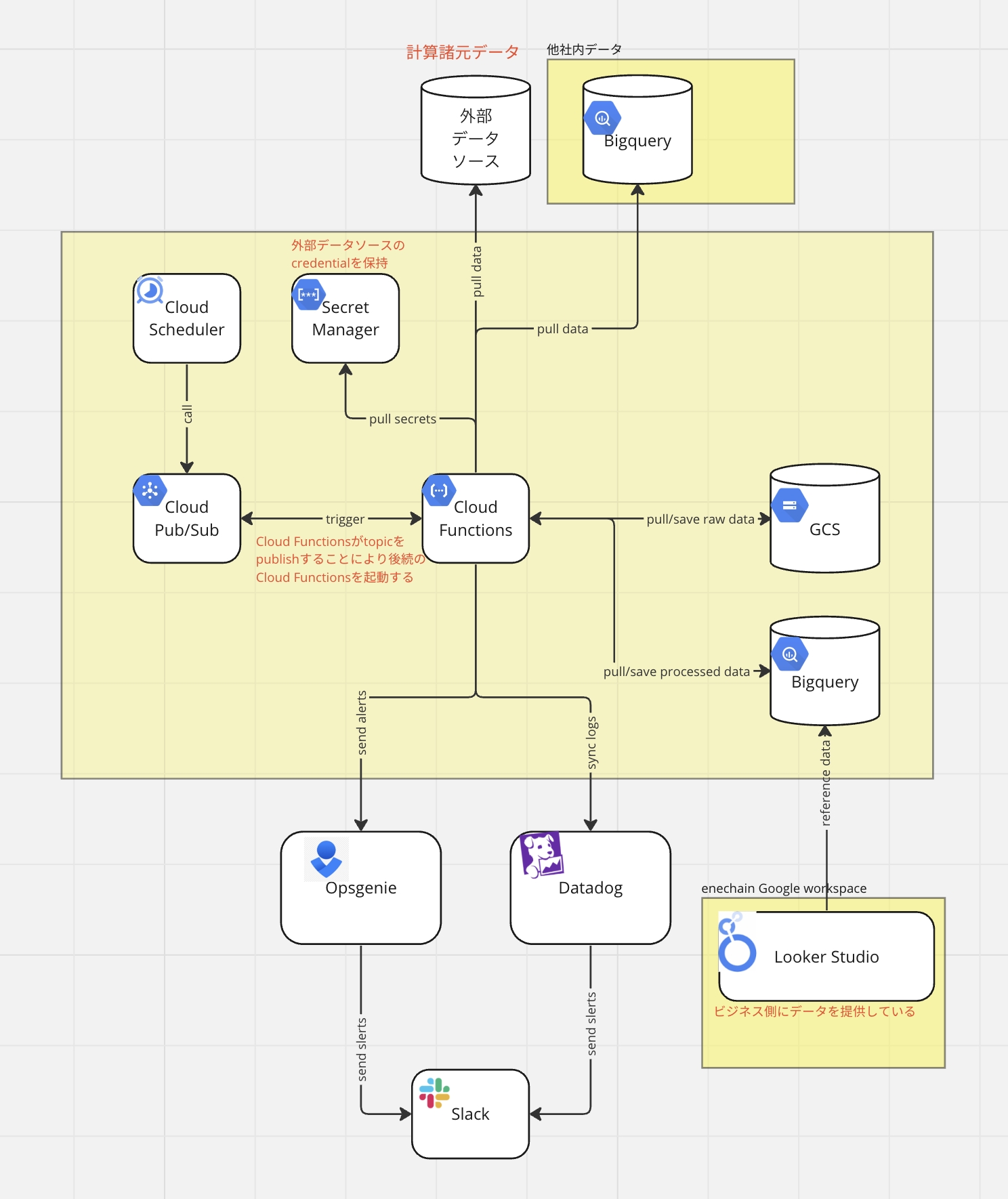 現行アーキテクチャ
現行アーキテクチャ
なぜ移行しているのかについて
次になぜ、現在パイプラインを移行しているのかについてです。
一般的にETLパイプラインにはデータの入口と出口の仕様が前提としてあり、その上でパイプラインの中身の処理としてパイプラインの両端のデータ仕様の変換を行うものだと思います。
今回のETLパイプラインの場合、出口の仕様が変わる頻度は高くない一方、外部のデータを取り込んでいる性質上、入口の仕様が変わることは頻繁にあります。 加えて仕様通りのデータが取得できる保証はなく、パイプラインがデリバーするデータの品質を担保するために入口のデータ品質にもそれなりに気を配る必要があります。
事実、外部起因による入口の仕様変更やデータの不具合、もしくは外部システム自体の不具合によりパイプラインの処理が正常に終了せずに復旧対応を行うことは数多く、社内の障害対応の大部分はこのETLパイプラインのものと言っても過言ではないです。
そういった背景の中障害の再発防止を含め現状のパイプラインの課題を整理したところ、実行環境/基盤に関しては以下のような課題を解決することが必要だと分かりました。
- パイプラインの細かい実行制御ができない
- 計算リソースに変えられない制限がある
- 環境構築のコストが高い
- 処理の状態を断片的にしかモニタリングできてない
以上の課題以外にも処理の構成やその他考慮したことがありますが、また別の機会に紹介したいと思います。
新 実行環境/基盤について
Argo Workflowsの起用
パイプラインの細かい実行制御の課題はCloud FunctionsをPub/Subで繋げていた構成から処理をワークフローエンジンに載せ替えることにしました。
ワークフローエンジンの選択としてはAirflowなども選択肢としてはありましたが、現行のパイプラインの運用がすでにかなり負荷になっていたため更に検証コストをかけるのではなく、社内の他サービスですでに採用されており立ち上げのコストを抑えられる点と実行制御という面では十分な機能を持っている点でArgo Workflowsにしました。
enechainにおけるArgo Workflowsの他システムでの採用例についてご興味があればこちらもご一読ください。
Cloud FunctionsからGKE+コンテナ化
Argo Workflowsを使用するにあたり実行環境をk8sに移すこととなったので計算リソースのコントロールは以前と比べては飛躍的に柔軟になりました。
また、Argo Workflowsで実行するためにアプリケーションのコンテナ化を行ったこと、k8sマニフェストを使用してワークフローなどのリソースを作成するようになったことによりアプリケーションレイヤーの変更に要する時間が大幅に短縮されて高頻度に変更ができるようになり新環境の構築も容易になりました。
実際に現行パイプラインでは40以上あるCloud Functionsの設定をterraformで管理しているためデプロイに少なくとも約20分かかりますが、Argo Workflowsではアプリケーションイメージのビルドを含め5-6分でデプロイを行うことができるようになっています。 その際にマニフェストの再利用を目的としたテンプレート作成を行っており、この後の実装パートで紹介します。
モニタリングシステムの統一
上記の現行アーキテクチャ図にあるようにOpsgenieとDatadogの2サービスをアラート送出とメトリクスモニタリング用途で導入しています。
これは初期の段階でパイプラインの実行時に異常が発生したらOpsgenieのAPIを叩くようにすでに実装された後にDatadog全社導入されたことが混在している事情としてあるのですが、今回の移行ではそれをDatadogに統一しています。
現行パイプラインのモニタリング・アラーティングの課題の中で最もクリティカルなものとして、ワークフローごとにモニタリングしづらいことがあります。 原因としては一つのワークフローの処理が複数のCloud Functionsにまたがり実行されているので、個々の処理の異常には気づけるがワークフロー単位でまとめて監視するのは難しく、アラートが発生時の影響範囲特定に時間がかかることが挙げられます。
これを解決するために今回Argo Workflowsではワークフローごとにアラートを仕分けるようにしています。 その際、Argo WorkflowsのメトリクスをDatadogに連携するにあたりある程度工夫が必要だったのでこちらも次の実装パートで詳細を紹介します。
実装
WorkflowTemplate manifestとtaskのテンプレート化
元々40近くのCloud Functionsで行なっていた処理をArgo Workflowsに載せ替えるにはそれなりの数のworkflowとtaskを定義する必要があります。 各々のtaskやworkflowでパラメーターが異なるとメンテナンスしづらくなるので、ワークフロー内のタスクはほとんど共通した環境変数やパラメーターを持つようにアプリケーション側で設計しています。 これによりタスク部分のmanifestを以下のように個別のテンプレートとして切り出して再利用できるようになりました。
task-template-ref.yaml
apiVersion: argoproj.io/v1alpha1 kind: WorkflowTemplate metadata: name: task-template-ref spec: templates: - name: task-template inputs: parameters: - name: target_module container: image: <image> command: [python, -m] args: - my_app.{{inputs.parameters.target_module}} env: - name: '<environment variable 1 name>' value: '{{workflow.parameters.variable1}}' - name: '<environment variable 2> name' value: '{{workflow.parameters.variable2}}' - name: task-template-2 inputs: parameters: - name: target_module container: image: <image2> command: [python, -m] args: - my_app.{{inputs.parameters.target_module}}
上記のtask-templateをDAG内のtaskのテンプレートとして使用したWorkflowTemplateの定義は以下のようになります。
sample-workflow.yaml
apiVersion: argoproj.io/v1alpha1 kind: WorkflowTemplate metadata: name: sample-workflow spec: entrypoint: main arguments: parameters: - name: target_subpackage value: sample_module - name: variable_1 value: <some_default_value> - name: variable_2 value: <some_default_value> templates: - name: main dag: tasks: - name: task1 templateRef: name: task-template-ref template: task-template arguments: parameters: - name: target_module value: '{{workflow.parameters.target_subpackage}}.task1' - name: task2 dependencies: [task1] templateRef: name: task-template-ref template: task-template arguments: parameters: - name: target_module value: '{{workflow.parameters.target_subpackage}}.task2'
task-template-ref.yamlとsample-workflow.yamlの紐付けはtemplateRefで行なっており、parameterなどが異なる場合や呼び出しているイメージが異なる場合はtask-template-2など複数のtaskのtemplateも定義できます。
また、workflowで使う変数としてはworkflow.parametersとinputs.parametersの2種類があります。 workflow.parametersの参照スコープは名前の通りworkflow全体になっており、それとは別にtemplateにinputsを設定することでよりスコープが狭いinputs.parametersも作成できます。 上記の例ではworkflow全体 (DAG内全てのタスクで共通) のものはworkflow.parametersに登録して、taskごとに変えたいものはinputs.parametersに登録するようにしています。
Workflowメトリクスの設定とDatadogでのアラート設定
今回の移行で達成したいモニタリングとアラートの必須最低要件は以下です。
- Workflowの種類ごとに成功率が監視できる
- Workflowの実行時間が監視でき、異常に長い場合に気付ける
- Workflowが失敗した際、再実行により復旧できた時に自動でアラートを解消する
Datadogでアラート管理を行い、これらの要件を達成するためには3つのカスタムメトリクスをArgo Workflows側から連携する必要がありました。
最終的にメトリクスの設定を含めたmanifestは以下のようになります。
apiVersion: argoproj.io/v1alpha1 kind: WorkflowTemplate metadata: name: sample-module-wf spec: entrypoint: main serviceAccountName: <your-service-account-name> activeDeadlineSeconds: 5400 metrics: prometheus: - name: custom_finished_workflows_count help: count of workflows which already finished labels: - key: template_name value: '{{= sprig.regexReplaceAll("(.*)-[^-]*-[^-]*$", workflow.name, "$1") }}' - key: status value: '{{workflow.status}}' counter: value: '1' - name: custom_current_workflow_duration help: duration of current workflow labels: - key: template_name value: '{{= sprig.regexReplaceAll("(.*)-[^-]*-[^-]*$", workflow.name, "$1") }}' gauge: value: '{{workflow.duration}}' - name: custom_last_workflow_result help: result of workflow executed lastly labels: - key: template_name value: '{{= sprig.regexReplaceAll("(.*)-[^-]*-[^-]*$", workflow.name, "$1") }}' gauge: value: "{{= sprig.ternary('0', '1', workflow.status == 'Succeeded')}}" ...
Workflowの種類ごとに成功率が監視できる
Workflowの種類ごとの成功率を監視するためにtemplate_nameとworkflow.statusをlabelとして付与したcounterを設けています。
- name: custom_finished_workflows_count help: count of workflows which already finished labels: - key: template_name value: '{{= sprig.regexReplaceAll("(.*)-[^-]*-[^-]*$", workflow.name, "$1") }}' - key: status value: '{{workflow.status}}' counter: value: '1'
このメトリクスを設定することでworkflowの実行が終了した際にカウントがvalueで設定した数値分(上記では1)増えます。 Datadog上でメタデータ(template_nameとworkflow.status)ごとにグルーピングすれば以下のように成功率を算出できるようになります。

Workflowの実行時間が監視でき、異常に長い場合に気付ける
Argo Workflowsでは実行中に取得できるリアルタイム実行時間とワークフロー終了時に確定する実行時間の2種類の実行時間関連のメトリクスを取得できます。
リアルタイム実行時間を取得したい場合
- name: custom_realtime_workflow_duration help: realtime duration of current workflow labels: ... gauge: realtime: true value: "{{duration}}"
ワークフロー終了後に確定する実行時間を取得したい場合
- name: custom_workflow_duration help: duration of current workflow labels: ... gauge: value: '{{workflow.duration}}'
ワークフローの実行時間が異常に長いことを監視したい場合、一見リアルタイム実行時間を監視した方が良いように思えますが、Datadogにこのリアルタイム実行時間を連携した場合、ワークフローが終了した後も一定時間メトリクスが残ってしまうため、メトリクスがDatadogに残留している間はアラートを解消できなくなってしまいます。 そこでリアルタイムの実行時間監視は諦めて、過去に計測した実行時間を参考にしてWorkflowTemplate自体にactiveDeadlineSecondsを設定してワークフローに実行上限時間を設けることにしました。 これにより異常に実行時間が長い場合はworkflowが上限時間超過でFail扱いになり、監視する必要があるものはワークフローの失敗だけとなります。
ただ、頻繁に上限時間を超えてしまうと計測してきた実行時間の統計値に影響してしまうため設定する値をメンテナンスする必要はあります。
Workflowのが失敗した際、再実行により復旧できた時自動でアラートを解消する
Datadogのアラート管理の仕組み上、手動でアラートを解消扱いにしてもメトリクスが異常を示している場合アラートが再送されてしまいます。 そこで失敗したworkflowの復旧が完了したら自動でDatadog側で復旧を検知してアラートを解消するようにする必要がありました。
個々のworkflow実行ごとの成功失敗を計測したい場合、上記先程触れたcustom_finished_workflows_countで事足ります。 しかしworkflow実行単位ではなくworkflowの種類ごとに成功したか否を継続的にヘルスチェックするためにはcounterではなく以下のようなgaugeメトリクスが必要になります。
- name: custom_last_workflow_result help: result of workflow executed lastly labels: - key: template_name value: '{{= sprig.regexReplaceAll("(.*)-[^-]*-[^-]*$", workflow.name, "$1") }}' gauge: value: "{{= sprig.ternary('0', '1', workflow.status == 'Succeeded')}}"
監視したい情報としては普及が必要か否かのバイナリー情報なのでternaryで値が0か1になるようにし、gaugeメトリクスなので個々のworkflow実行が終了した際に値が上書き更新されるようになります。 あとはDatadogの監視設定で以下のようにworkflow.statusがSucceeded以外の場合(上記では数値上1と同義)にアラート条件として指定すればworkflow種別ごとにヘルスチェックを行うことができます。

実際にDatadog monitorのstatusで再実行による復旧が行われた時にメトリクス (紫線) が1から0になりAlertステータスからOKに変化していることが確認できます。

おわりに
今回はデータパイプラインをCloud FunctionsからArgo Workflowsに移行した際に工夫をしたことについて紹介しました。 この他にもアプリケーションレイヤーやデータストアなど実行環境以外のアーキテクチャについても今後記事にしたいと思います。
このようにenechainではモダンな技術への関心を高く持ち、サービスの改善に繋げ、巨大なマーケットを支えるデータ基盤を一緒に構築する仲間を募集しています。もし興味を持っていただけました場合はぜひご応募お待ちしております!