

この記事は enechain Advent Calendar 2023 の22日目の記事です。
はじめに
enechainデータプラットフォームデスク エンジニアのakizhouです。
我々データプラットフォームデスクは業務の一部として、enechainが提供するeCompassと呼ばれる「エネルギー関連データ提供SaaS」で使用されるデータ収集、集計を行うデータパイプラインを開発運用しています。
このデータパイプラインは創業以来使用され続けてきましたが、運用してきた上で直面した様々な課題を抱えており、現在はアーキテクチャから根本的再設計と移行を進めています。
本記事では、データパイプラインの新しいアーキテクチャにおいて解決したい課題の一部を抜粋して、それに対しての解決策として検討しているツールDagsterについて少し紹介したいと思います。
注意)この記事はDagsterの導入事例の紹介ではありません。
現行のデータパイプライン
データパイプラインの全体像
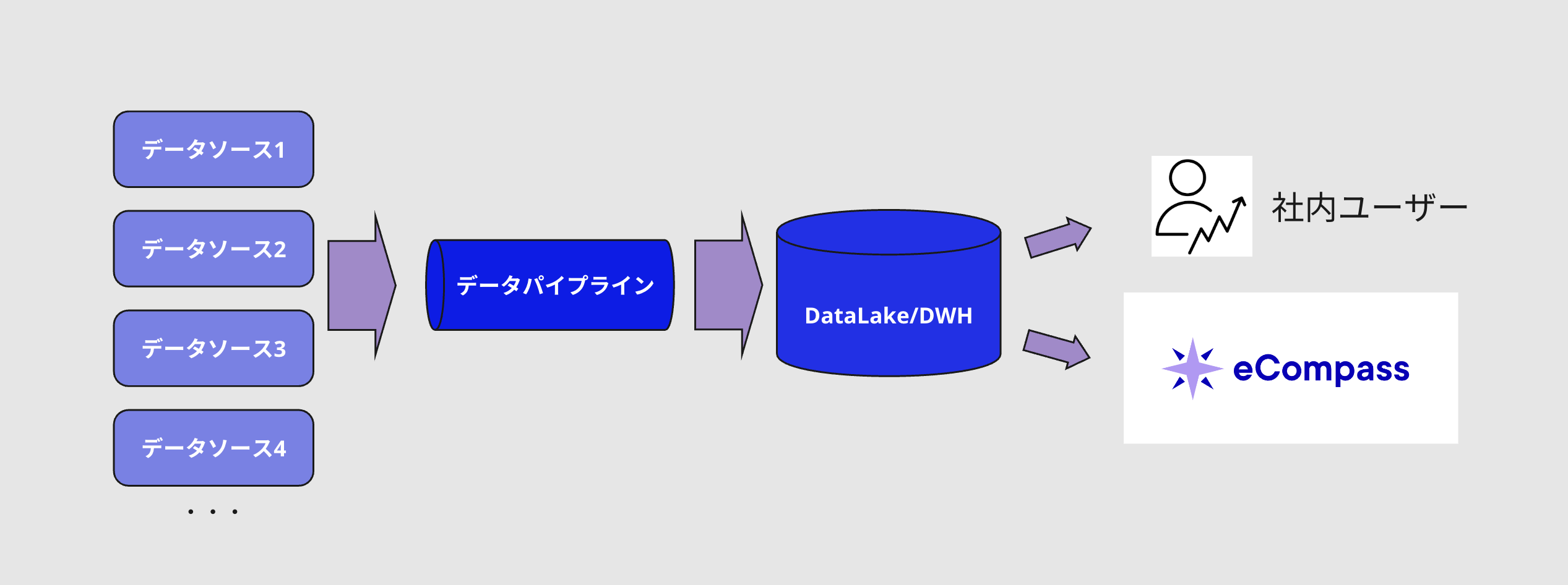
こちらのデータパイプラインは先述のeCompassやその他の社内のデータ利用ニーズを中心に展開されています。
このデータパイプラインの入り口では様々なソースからデータを収集しており、処理を施されたデータは最終的にDWHであるBigQueryに書き込まれます。そしてeCompassを含めデータ提供時にはこのBigQueryが参照されることなります。
データソースとそれをもとに作成されるテーブルの関係性としては単純に1:1、N:1、1:Nなものもあれば複雑な依存関係を持つN:Nになっているものもあります。
このように単純でないデータソースと提供先の関係性がビジネス要件的に存在する性質上、提供しているデータの品質や信頼性、透明性といったことを管理するにはデータリネージを明確にすることが重要になります。 現状我々のチームではこのデータリネージを下記のようなドキュメントとして手動で更新管理するようにしています。

Cloud Functionsとそれに関連するテーブルを含めたデータリネージ
現状の課題
続いて現行データパイプラインの一部詳細とその課題について説明します。
以前こちらの記事でも少し触れましたが弊社のデータパイプラインはPub/SubとCloud Functions (1st gen) の組み合わせによるイベントドリブンなアーキテクチャになっています。 つまり実際の処理はCloud Functions内で行っており、Cloud Functionsの仕様上9分の実行上限時間と8192MBのメモリ上限の制約があります。
現在Cloud FunctionsはTerraformにより状態管理をできるようにしていますが、Cloud Functions内に一つの関数をデプロイするのに少なくとも3分かかるため安易に数を増やすとデプロイ時間が伸びるといった事情もあります。
これらのことから開発時には、Cloud Functions内に関数が増えすぎるとデプロイ管理が複雑になるため、できる限り処理をまとめたいという考えが自然と働きます。
しかし、時間とメモリの制約があるため、処理をどれだけ効率的にまとめられるかはケースバイケースです。
したがって、処理をまとめたいと思っても実際には難しい場合があり、結果として関数ごとに処理のまとまり具合が異なり、一貫性がない状態となっています。
このような背景から現行データパイプラインでは一つのCloud Functions内の関数とそれが書き出しを行うBigQueryのテーブルという側面においても、1:1、N:1、1:N、N:Nの関係性が存在します。
また「Cloud Functionsとそれに関連するテーブルを含めたデータリネージ」(上図) はソースコードを参照しながら手動で作成しており、この方法はメンテナンスコストが高い上に更新時に人為的ミスを含むリスクもあります。
加えて、Cloud Functionsで構成されたパイプラインの処理依存関係は別ドキュメントとして存在しており、こちらも現状手動で更新する作業が発生しています。
ここまでの話を整理すると現行データパイプラインには以下の3つの課題があります。
- 処理の依存関係視覚化問題: ドキュメントにて処理の依存関係を手動で更新管理する必要がある
- 処理とデータの関係性問題: ドキュメントにて複雑な処理単位とデータの依存関係を手動で更新管理する必要がある
- データリネージ問題: ドキュメントにて複雑なデータリネージを手動で更新管理する必要がある
他にも課題がいくつか存在しますが、今回は上記の課題3つにフォーカスしていきます。
課題解決へのアプローチ
1. 処理の依存関係視覚化問題への対応
まず、処理の依存関係視覚化問題に対しては、ワークフローエンジンを導入するのが一つの解決策です。ワークフローエンジンの機能によりDAGを通じて処理の流れと依存関係が視覚的に明確になり、更新管理が楽になると考えています。
2. 処理とデータの関係性問題への対応
次に、処理とデータの関係性問題に関しては、タスクとデータを1:1に関連付けることで、複雑性を減らし管理を容易にします。ここに関しては後述の「Task-centricとData-centricの比較」で補足説明します。
3. データリネージ問題への対応
データリネージ問題については、上述のタスクとデータの1:1関連付けがその解決に寄与します。この方法を採用することで、データリネージの更新が実質的に自動化され、手動での更新管理の負担が軽減されます。
これらのアプローチについては、ワークフローを構成する際の考え方、すなわちTask-centric(タスク中心)とData-centric(データ中心)の違いを理解するとより分かりやすくなります。
Task-centricとData-centricの比較
Task-centricなアプローチでは、ワークフローはタスクの集合として捉えられ、各タスクが特定の操作を行うよう設計されています。
各タスクの依存関係は、データのフローよりもタスクの実行順序に重点が置かれます。この方法は、タスクとデータの関係性が明示的でないため、タスクとデータ間の関係性に気を配る必要があります。
また、task-centricのデメリットとして挙げられることの一つとして、データに異常を発見した場合に関連するタスクを特定する必要する際に正確なデータリネージなどのドキュメントが必要です。
対してdata-centricなアプローチは実行単位とデータの単位の関係性を1:1に保つ制約は生まれるものの、以下のようなメリットがあります。
- データを更新する際に実行が必要なタスクを瞬時に特定できる
- データがいつ更新されるか把握しやすい
- データ間の依存が瞬時に特定できる
つまりtask-centricとはデータの観点で手続型なアプローチであるのに対し、data-centricは宣言的なアプローチと考えることができます。
加えてdata-centricはデータリネージの変更を要する実装が追加である際、処理の変更も考えやすくなる開発上のメリットもあります。
例として以下に同じデータに対するワークフローをtask-centric構成とdata-centric構成のものをDAGでみた場合の比較をします。
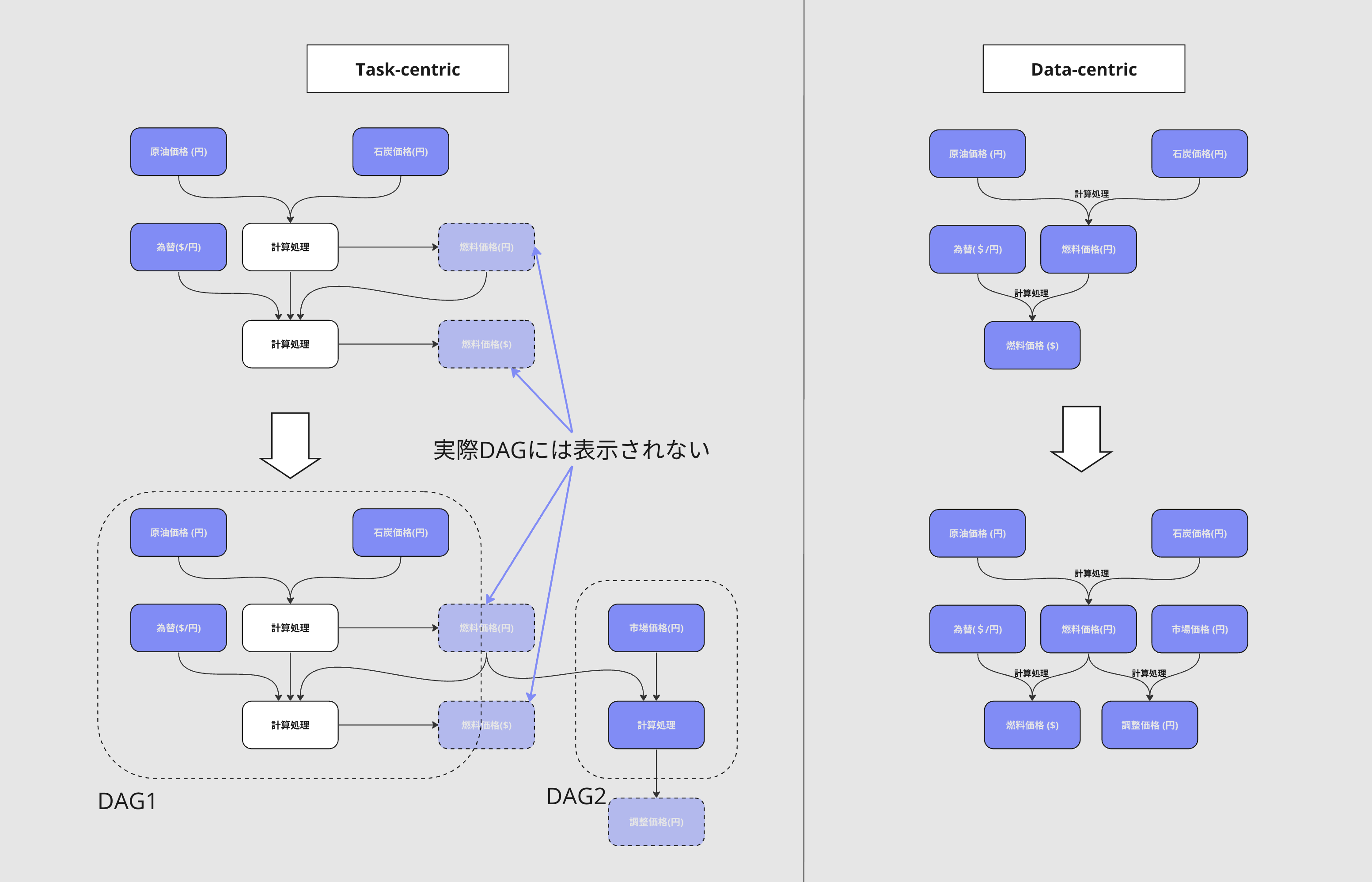 図には載せましたが、task-centric構成では処理によって生成されたデータと処理が使用しているデータの一部がDAG上で可視化されていません。
そのためデータの結びつきがあるにも関わらず、DAG1とDAG2が個別に存在することとなってしまします。
一方data-centric構成ではデータの結びつきが全て表現されているため視覚的に分かりやすいです。
図には載せましたが、task-centric構成では処理によって生成されたデータと処理が使用しているデータの一部がDAG上で可視化されていません。
そのためデータの結びつきがあるにも関わらず、DAG1とDAG2が個別に存在することとなってしまします。
一方data-centric構成ではデータの結びつきが全て表現されているため視覚的に分かりやすいです。
補足としてdata-centricな構成でDAGのエッジで計算処理を表現していますが、これは説明上の表記で、実際の計算処理は各ノードで定義されています。
Data-centricなDAG構成は多くの利点があるものの、現実問題N:1、N:Nのように一つのテーブルが複数のテーブルに依存している場合、先行データが異なる時間帯で更新されるもしくは1日に数回更新されるといったことがあります。
これを考慮するにはdata-centric、task-centricとは別にN:1の後続処理はどういう条件で処理開始をするのかを考える必要がありますが、今回はスコープ外とします。
data-centricな実装
現在、data-centricなワークフローを実装したい場合、Dagsterが最適な選択肢だと考えています。
Dagsterはデータの文脈において、従来のtask-centric構成前提で開発されたワークフローエンジンの課題を解決するという明確な目的のもとに設計開発されています。
実はこの記事で説明してきたdata-centricな考え方自体、Dagsterの設計思想の根幹にあるためdata-centricなワークフローを実装するためのクラスが多数用意されています。
例をあげると、以下のようなコードでdata-centricなDAGを実装できます。
import pandas as pd import requests from dagster import asset, define_asset_job @asset() def data1(): url = "http://example.com/data.csv" response = requests.get(url) response.raise_for_status() return pd.read_csv(pd.compat.StringIO(response.text)) @asset() def data2(): url = "http://example.com/data2.csv" response = requests.get(url) response.raise_for_status() return pd.read_csv(pd.compat.StringIO(response.text)) @asset() def transform_data(data1: pd.DataFrame): return data1[data1['column_name'] > 0] @asset() def combine_data(data2: pd.DataFrame, transform_data: pd.DataFrame): return pd.merge(data2, transform_data, on='key_column') all_assets_job = define_asset_job( name="all_assets_job", selection=["fetch_csv_data", "transform_data", "combine_data"] )
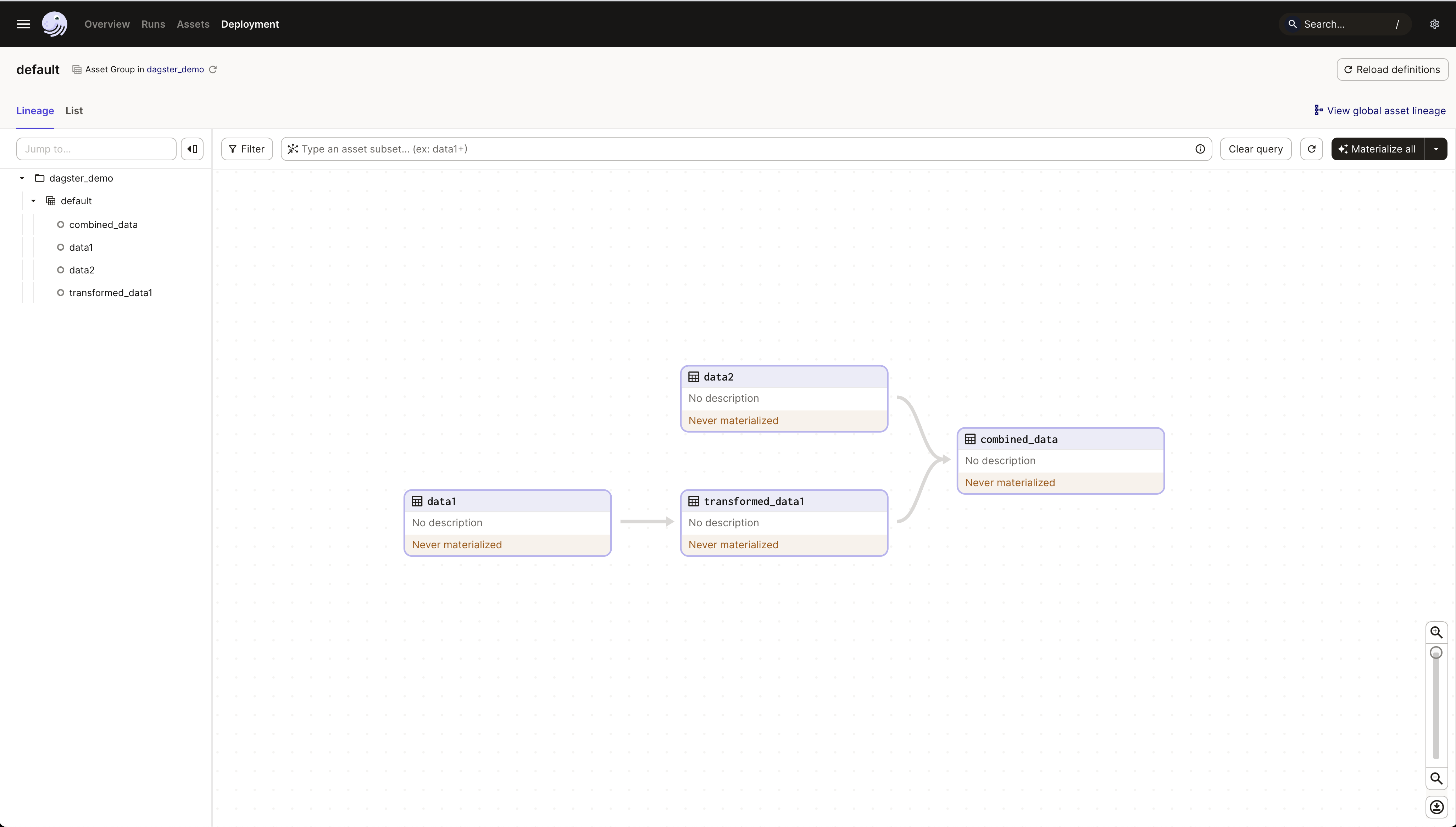
DagsterのUIを利用することで、タスクの状態(例えばスクショ中のNever materialized)を確認できます。また、ノードを選択して直接処理を実行するなど、様々な操作が行えます。
この記事ではこれ以上の深掘りはしませんが、Dagsterは引き続き活発に開発が進められています。
今年2023年のLaunch Weekでは以前紹介したGreat Expectationsとも高い親和性を持つような様々な機能追加や改善がリリースされたり、Dagster Universityのようなデータオーケストレーションツールとしての概念的な部分の理解をサポートする取り組みなども強化され、今後ますます発展と普及が期待できます。
最後に
今回はデータパイプラインでの課題を一部ピックアップしてdata-centricなワークフロー構成とDagsterでの実装例を紹介してみました。現在データパイプラインの移行途中で、Dagsterも視野に入れた検証を進めています。 このほかにもデータプラットフォームではデータの管理とデータパイプラインの保守運用について日々議論と技術検証を繰り返しながら改善する取り組みを行っています。
機会があれば、アーキテクチャ移行に関連する他の取り組みとや実際に移行をした環境で運用を行った所感についても記事にして紹介したいと思います。
このようにenechainではモダンな技術への関心を高く持ち、サービスの改善に繋げ、巨大なマーケットを支えるデータ基盤を一緒に構築する仲間を募集しています。もし興味を持っていただけました場合はぜひご応募お待ちしております!
明日は@nakker1218による記事になります。ぜひチェックしてみてください。