

Data Platform Desk (以下:DPD) の新卒駆け出しエンジニア akizhou です。
今回は、enechain のアプリケーションを支えるデータパイプラインに Great Expectations というデータ品質監視ツールを導入する過程で得た知見を共有したいと思います。データ品質向上を目指す皆さんに役立つ情報が提供できれば幸いです。
はじめに
enechain ではデータ活用によりユーザに価値提供しており、サービスの有償化や事業規模拡大に伴いデータ品質の担保が重要性を増しています。
しかし、さまざまなデータソースから得られる異なる形式/粒度/更新頻度のデータを扱うパイプラインの品質を人力で管理するのはコストが非常に高く、データパイプライン運用のために開発の時間が犠牲になることも多々ありました。
さらに、パイプラインの複雑さから、データの不整合や欠損が発覚した際の原因特定が難しく、異常検知の遅延も頻発していました。
これらの課題への対策を行い、組織全体でデータの信頼性を向上させたいと考え、今回 DPD ではデータ品質監視ツールを導入することにいたしました。
要件
前提として、弊社のデータパイプラインでは、Google Cloud Platform の Cloud Scheduler と Cloud Functions を用いて定期的に処理を行い、後続処理は Pub/Sub を介して実行されます。
現状テーブルデータしか扱っておらず、様々な形式の生データ(CSV、XML、JSON、PDF)を Pandas DataFrame に変換して処理し、中間生成物や出力は BigQuery に保存しています。
通知監視には Datadog と Slack を利用し、アラート通知を Slack で受け取るよう設定しています。
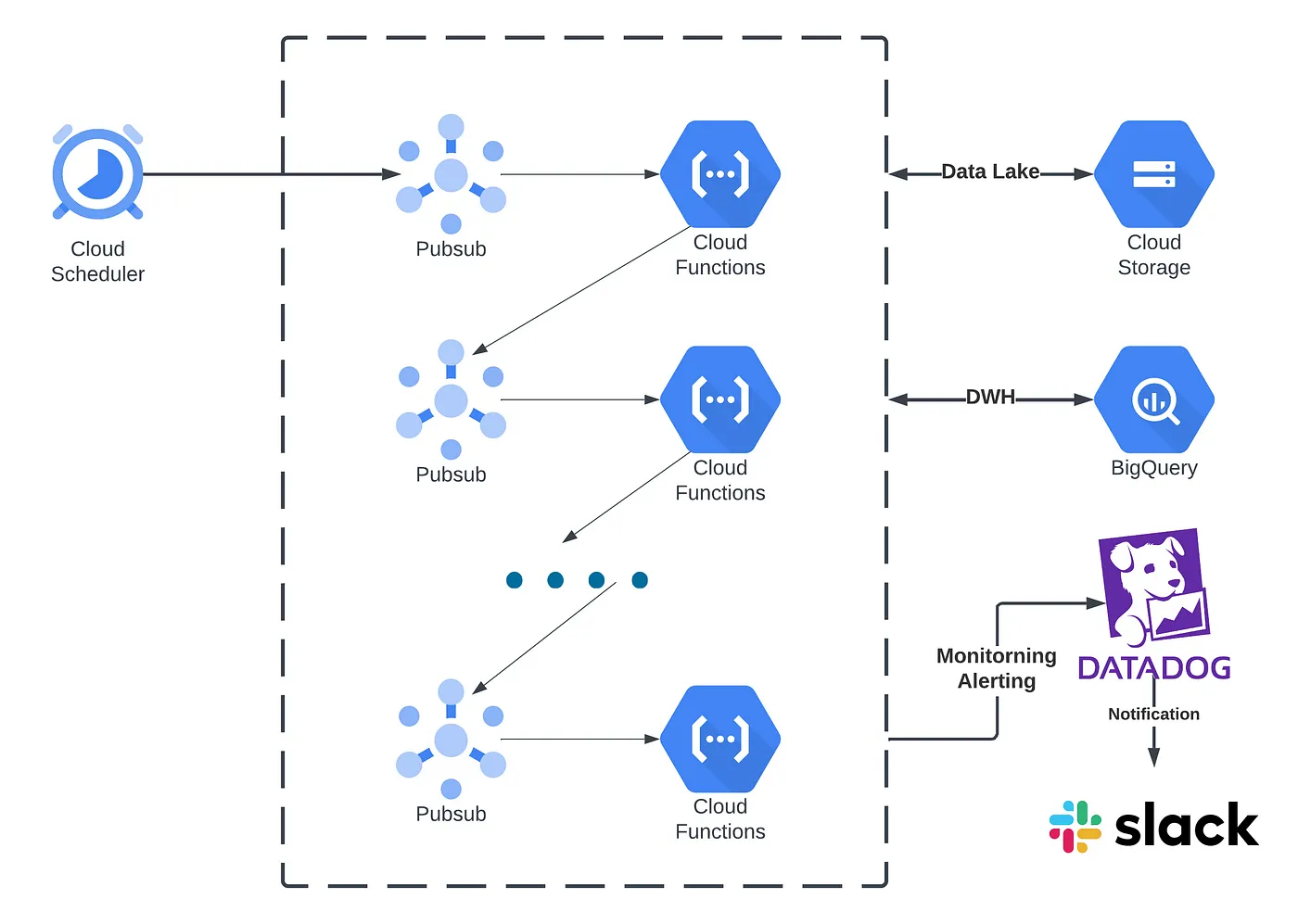
アーキテクチャ上、データの品質を管理する仕組みが存在せず、SLA を策定する際にそもそも品質を計測できていないという致命的な課題があるため、今回ツールを比較する際の要件として、導入コストの低さと既存のアーキテクチャに対応していることが重要な要素となっています。それを踏まえ、以下の要件を選定する際の考える基準としました。
Must
- テーブルデータ(Pandas DataFrame)に対応している
- 導入コストが低い(ビルトインで監視項目を提供している)
- Slack に通知できる
Nice to have
- 品質レポートなどで監視状態の可視化ができる
技術比較
「Data validation」を中心に選定候補を探したところ下記の有望なツールを見つけました。
- Great Expectations (GX):データ品質監視と検証に特化したオープンソースの Python ライブラリ。JSON もしくは Jupyter notebook を使用してデータパイプライン内のデータセットに対して品質基準(期待値)を定義できる。データのドキュメンテーションやプロファイリング機能も提供し、データの可視化や理解を手助けするツールも備わっている。
- PipeRider:データパイプラインの自動化プラットフォームで、さまざまなデータ統合や変換機能を提供している商用製品。データパイプラインの設計や管理のための視覚的なインターフェースを提供している。さらに、複数のデータソースや形式をサポートし、データ品質を保証するための組み込みのデータ検証、監視、アラート機能を提供している。
- Pydantic:Python 用のデータ検証と設定管理ライブラリ。データモデルを定義し、それらのモデルに対してデータを宣言的に検証できる。
- Voluptuous:シンプルで直感的なデザインを目指したデータ検証用の Python ライブラリ。軽量でスキーマや値の範囲をバリデーションできる。
- Cerberus:Python 用の軽量で拡張性のあるデータ検証ライブラリ。辞書ベースの構文を使用して、データスキーマを定義して検証できる。
各ツールが要件をどの程度満たしているかについて調査し、主観的ではありますが以下のように評価しました。
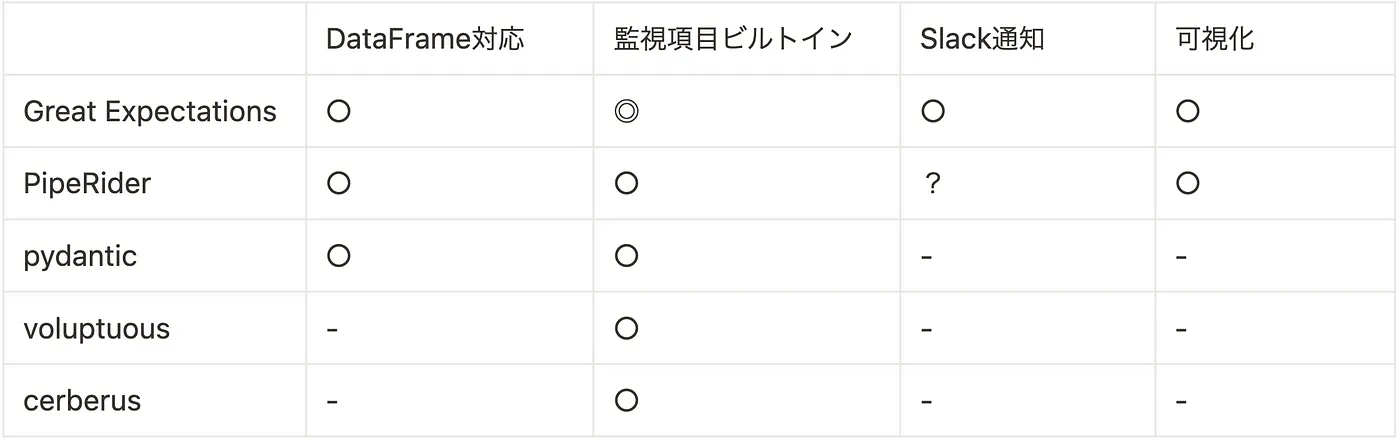
Pandas DataFrame に対応しており、ビルドインで使える監視項目が豊富で実装コストが少なくすぐに利用そうなツールとして Pydantic、PipeRider、Great Expectations の 3 つが候補として残りました。
そして Slack 通知に関して、Pydantic ではバリデーションに引っかかるとエラーをレイズする仕組みなため、他の実行エラーとの区別が難しくなる可能性があり、監視ツールとしてはやや不利と判断し、除外しました。また PipeRider の Slack 通知機能について、調査時点では公式のリポジトリに Slack 通知の仕組みらしきコードも存在せず、実装予定であると考え評価は「?」とさせていただきました。
最後の比較として PipeRider と Great Expectations は、どちらも Modern Data Stack で Data Quality Monitoring ツールとして紹介されており、両者の要件を満たす能力も似ていますが、以下の点から現在の状況では Great Expectations の方が成熟していると考えられます。
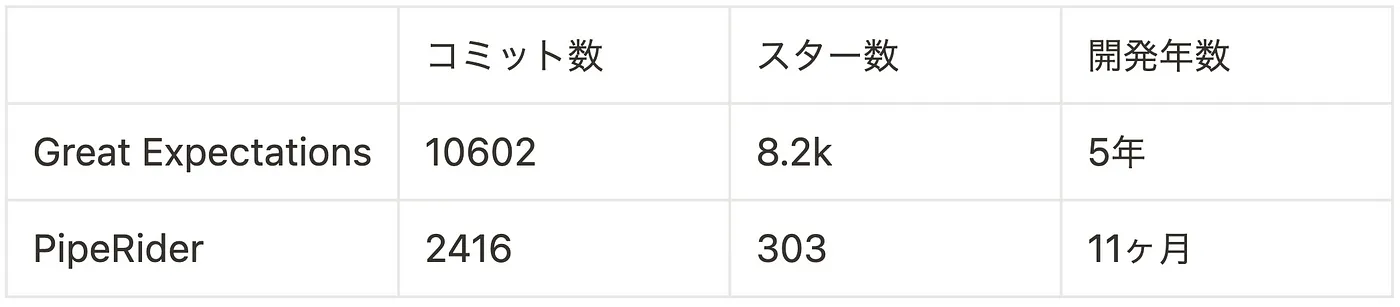
ここで少し原点に戻りますが、今回の課題である「データの品質を監視したい」に対する業界標準はまだ明確に存在しないと思われます。Great Expectations の公式がこの問題を解決しようとしていると明言しているところから将来性を感じたのと現時点での成熟度が他の選択肢よりも高いため、今回 DPD では Great Expectations を採用しました。
Great Expectations の検証
実際に Great Expectations (以下:GX) を利用してみたので、利用方法や所感などを記載します。
テーブルデータに対応している
GX には Datasource という概念が存在します。
これは品質監視の対象となるデータではなく、GX への入力データのシステム仕様をさしており、BigQuery や MySQL などの Database や、Pandas もしくは Spark を介したインメモリの DataFrame にも対応しています。
great_expectations.yamlという GX の設定ファイルに、事前に使用する Datasource を以下のように定義しておき、実行時に指定することで GX がデータシステムへのアクセスをハンドリングしてくれます。
datasources: runtime_dataframe: module_name: great_expectations.datasource class_name: Datasource execution_engine: module_name: great_expectations.execution_engine class_name: PandasExecutionEngine data_connectors: default_runtime_data_connector: module_name: great_expectations.datasource.data_connector class_name: RuntimeDataConnector batch_identifiers: - default_identifier_name
品質監視項目(バリデーションテスト)を定義/実装するコストが低い
GX で監視項目を設定するには Expectations Suite という Expectation (バリデーション項目)の集まりを定義する必要があります。Expectations Suite は JSON ファイルとして保存され、Checkpoint というバリデーションの実行単位で指定して活用します。
そしてその JSON は以下の 4 つの方法のいずれかを使って作成することができます。
- JSON を直接記述
- Jupyter Notebook でインタラクティブに記述
- 標準機能の Profiler と Data assistants を使用して自動生成
- カスタムでスクリプトを作成
Expectations Suite の作成については、初めは公式のチュートリアルを参照して学習することが効率的だと思いますので割愛します。
Slack に通知できる
通知設定は、Checkpoint 内の action_list で定義できます。
Checkpoint は YAML ファイルとして保存され、通知などの変更頻度が低い設定をテンプレートとして持っておくこともできます。
以下の例では、バリデーション実行結果を成否に関わらず、すべて同じ Slack チャンネルに通知するように action_list で設定したテンプレートになります。
name: base_checkpoint config_version: 1.0 module_name: great_expectations.checkpoint class_name: Checkpoint action_list: - name: store_validation_result action: class_name: StoreValidationResultAction - name: store_evaluation_params action: class_name: StoreEvaluationParametersAction - name: update_data_docs action: class_name: UpdateDataDocsAction site_names: - gcs_site - name: send_slack_notification action: class_name: SlackNotificationAction slack_webhook: secret|projects/${GCP_PROJECT}/secrets/secret_name notify_on: all notify_with: - gcs_site renderer: module_name: great_expectations.render.renderer.slack_renderer class_name: SlackRenderer
上記のテンプレートをもとに checkpoint を作成すると以下のようになります。ここでは先述のruntime_dataframeという Datasource と接続しています。
name: sample_checkpoint config_version: 1.0 template_name: base_checkpoint_template module_name: great_expectations.checkpoint class_name: Checkpoint evaluation_parameters: {} runtime_configuration: {} validations: - batch_request: datasource_name: runtime_dataframe data_connector_name: default_runtime_data_connector data_asset_name: some_asset_name expectation_suite_name: name_of_an_expectation_suite
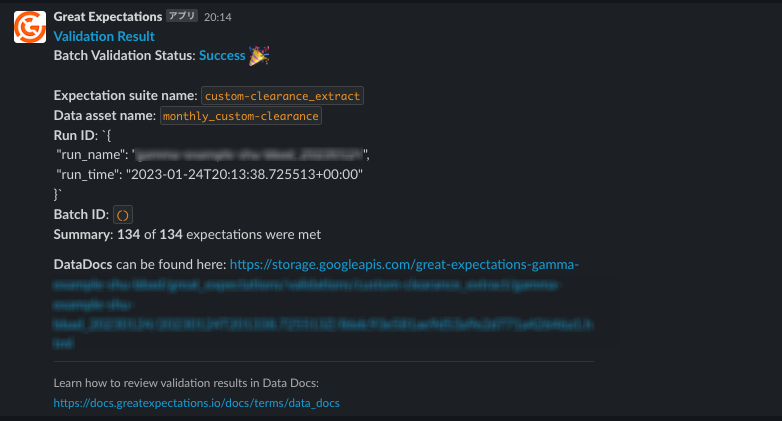
実際に Checkpoint を実行するとこのような通知がきます。
監視状態の可視化ができる
Great Expectations で Data Docs という HTML ドキュメントを生成することができます。
この Data Docs では実行環境で定義されている Expectation Suites や、実際のバリデーションの実行結果を確認することができます。
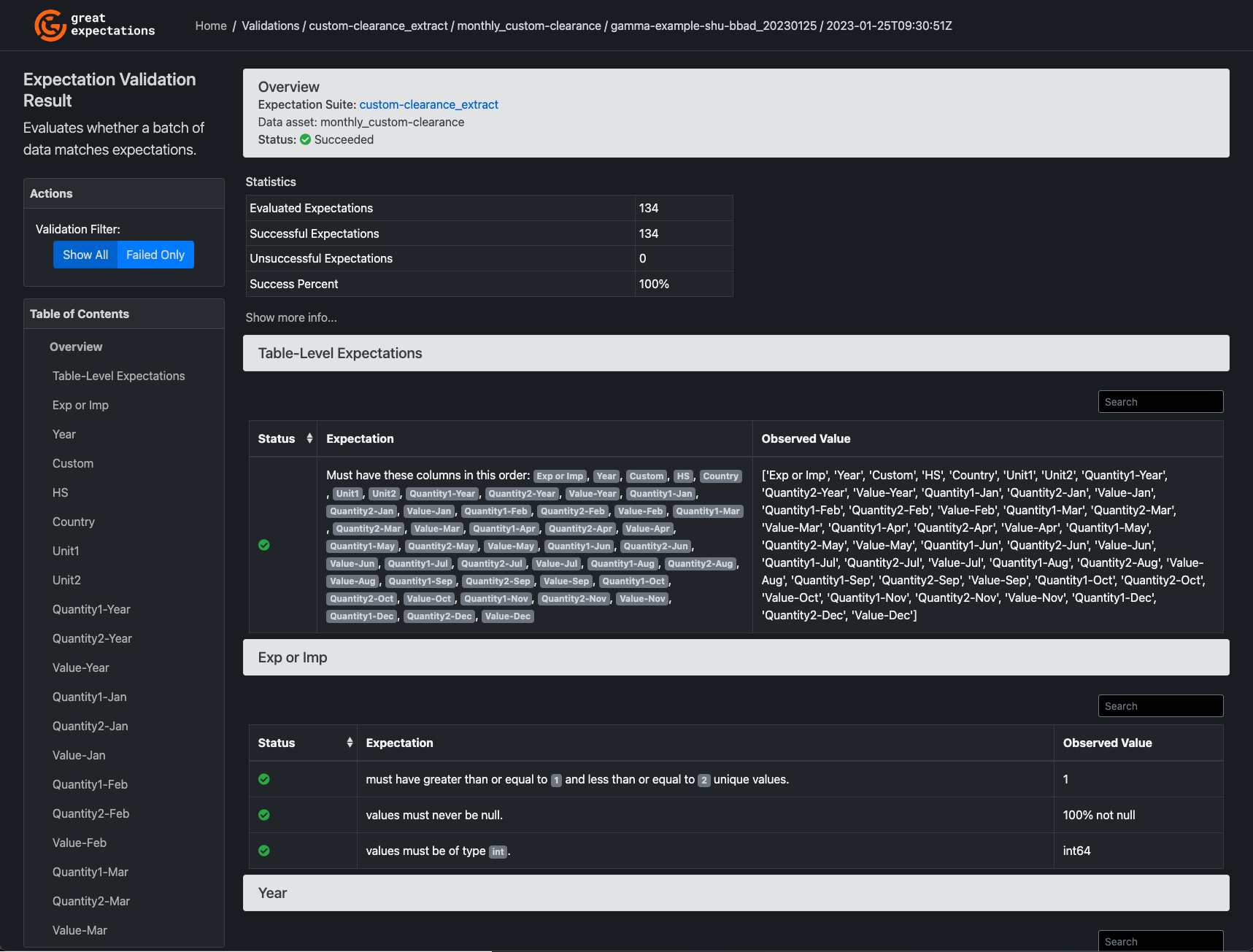
現状の OSS 版では自前でホスティングする必要がありますが、公式からの情報によれば、今後 GX Cloud 版では SaaS の一部として提供される予定だそうです。
検証を経て感じた Pros and Cons
Pros
- 公式ドキュメントが充実している
- 基本宣言的な構文を使用するため、監視項目の定義が容易である
- カスタムの監視項目を定義でき拡張性がある
- Profiler を使用して監視項目をサンプルデータから自動生成できる
- Slack 通知や外部ストレージの保存などが比較的簡単である
- Data Docs を使用することで、監視項目とバリデーション結果を一括で確認することができる
- Slack コミュニティが活発であり、公式からアドバイスを得ることができる
Cons
- コンセプトが多く学習コストが高い
- まれに古いバージョンのドキュメントに行き着く(サイトの見た目が違うのですぐ気付ける)
- Expectation Suite、Checkpoint、Asset name、Batch Identifier などの命名規則を決める必要がある
- Data Docs はホスティングする必要があり、実際に活用するためには手間がかかる
今後の課題
現状は、Data Docs をホスティングできていないため、Slack 通知に添付されたリンクを見に行く運用になっています。この運用で問題の発生箇所はわかるのですが、過去のレポートを UI から見に行くことが出来ないので改善したいところです。
また、ETL の各段階やデータウェアハウス自体にも Checkpoint を導入し、ロジックとそのユニットテストではカバー仕切れなかった異常に気付けるようにパイプライン全体のロバストネスを担保できるようにしていきたいと考えています。
ただし、Checkpoint も一概に等しい緊急度で対応が必要な訳ではないため、通知先を適切に分けるなど仕組みで工夫すればより効率的な運用になると思います。
そして、データは変化するものですので Expectation に定義した閾値等を Evaluation Parameter を活用して定期的に自動更新するなどのメンテナンスも必要です。 ボラティリティが高いデータについては、どの範囲なら許容するか、サービスレベルの基準にも依存すると思いますがドメインエキスパートなどの介入が必要な場合があることにも留意する必要があります。
これらの課題を解決していくためにも、これからはアーキテクチャ設計と運用体制を改善していくことが必要だと考えています。
最後に
今回は、Great Expectations の導入について紹介してみました。
Great Expectations によりパイプライン実行時の DataFrame のバリデーションは実現出来ましたが、運用面を考えるとまだ課題は残されています。
データ品質管理監視ツールもまだ発展途上であり、スタンダードが存在しないため、今後の Great Expectations や他のツールの動向にも注目していきたいと思います。
機会があれば、アーキテクチャの問題を解決した後の所感や運用、チェックポイントを設定すべき箇所など、データ品質監視の考え方について紹介していきたいと思います。