

この記事は enechain Advent Calendar 2023 の8日目の記事です。 昨日は @26takafuji の メガベンチャーからスタートアップのデータ基盤に転職した話 でした。
はじめに
enechain のデータプラットフォームデスクで、今年から新卒データエンジニアとして働いている菱沼です。
本記事では、データ品質向上を目標に、ロギングを適切に設計・実装する手法をご紹介します。
我々のチームが抱える課題点を解決するために、どのような方法でロギングを構築したかを実コードを交えながらご説明いたします。 ぜひ最後までお付き合いください!
背景
enechainでは、世界中のエネルギーに関するマーケット価格を分析しやすい形で視覚化するデータ提供サービスである eCompass を提供しています。 我々は、電力取引の公平性の担保という観点で、常にお客様に正確かつ即時にデータを提供することが求められています。 提供しているデータの品質が担保されていることは、我々のサービスの信頼性に直結すると言え、データ品質の向上は我々の最優先事項の一つです。
そこで、本記事では eCompass を通じて提供するデータの品質向上を目標に、どのような方法でそれが実現できるか検討し、実装した事例及び実際の効果について説明します。
検討事項
解決したいスコープ
データ品質と一概に言っても、様々な側面があります。 そこで、我々が運用しているデータパイプラインにおいて、データ品質の観点で何を最も重要視している項目であるかをチーム内で議論しました。
正確性 (Accuracy)
データに誤った情報が含まれていないことは、最重要項目の一つです。 eCompass は、マーケットの参入者がフェアな電力取引価格を把握する事を目的としているため、プロダクトに載せるデータは常に正確である必要があります。
即時性 (Timeliness)
我々が創り出している電力マーケットは、外部環境の変化によって常に価格が変動します。 例えば、他の取引所で取引されている燃料の価格によっては、電力価格が変動することがあります。 そのため、これら重要指標が提供された場合、即時にデータを取り込み、プロダクトに反映させる必要があります。
現行システムの課題点と解決方法
我々が運用しているデータパイプラインがよりデータ品質を高く保つためには、以下のような課題点がありました。
外部データソースに異常値が含まれていることがある
eCompass というプロダクトの特性上、外部データソースからデータを取得するケースが多いです。 そのため、外部データソースに異常値が含まれていると、実装が正しい場合でも適切にデータ集計ができないことがあります。 仮に異常値が含まれていた場合、データの正確性を担保するためには、データの不正に気づき、テーブルに異常値を混入しないようにする必要があります。
出力されているログが少ない
データパイプラインの処理において、どのような処理が行われているかを把握するためには、ログが不可欠です。 もし処理が異常終了してしまった場合、ログが適切に出力されていないと、なぜ異常終了したのかを把握するのにより多くの時間を要してしまいます。 結果として、データの即時性を担保することができなくなってしまいます。
1点目の課題については、以前Great Expectationsで始めるデータ品質管理 で記事にした通り、テーブルデータに対するGreat Expectationsを用いたvalidationも、まだ完了はしていないものの進行中であり、解決に向かっております。
一方で、2点目の課題は当時まだ改善の検討ができておりませんでした。
ただ、この問題が解決されない限り現行のデータパイプラインの処理にブラックボックスの箇所が多く残ってしまうことになります。
ログを挿入することによって、処理したデータの行数などの計測が可能になり、結果としてアプリケーションに対する継続的モニタリングを行うことができるようになるという点で、ロギングは重要な要素であると言えます。
そこで、データパイプラインのアプリケーションコードにログ挿入を行うことで、observabilityを向上させることが優先して達成すべき項目であると考えました。
ログの種類
ロギング実装を行う際にチームメンバー間の認識のズレがあると、各個人のルールでログを出力することになり、一貫性を欠くことになります。 そこで、チーム内で出力すべきログの種類を洗い出し、チーム内での合意形成を行いました。
ログの種類は大きく分けて、以下の2種類に分類しました。
| ログの種類 | 内容 | 出力タイミング |
|---|---|---|
| アプリケーションログ | アプリケーション本体の処理の情報に関するログ | 処理の進捗状況に応じて出力 |
| システムログ | 処理の実行時間、アプリのバージョンや実行環境に関するログ | データパイプラインの処理の終了時に1本のみ出力 |
また、アプリケーションログについては、より詳細に以下のような種類に分類しました。
| アプリケーションログの種類 | 内容 |
|---|---|
| オペレーションログ | データパイプラインの進捗状況を出力するログ |
| エラーログ | エラーの内容を出力するログ |
| データアクセスログ | BQ・GCSなどへのアクセス時に出力するログ |
| リクエストログ | APIリクエスト時に出力するログ |
システム構成
今回構築したロギングシステムの構成図は以下のようなイメージとなります。
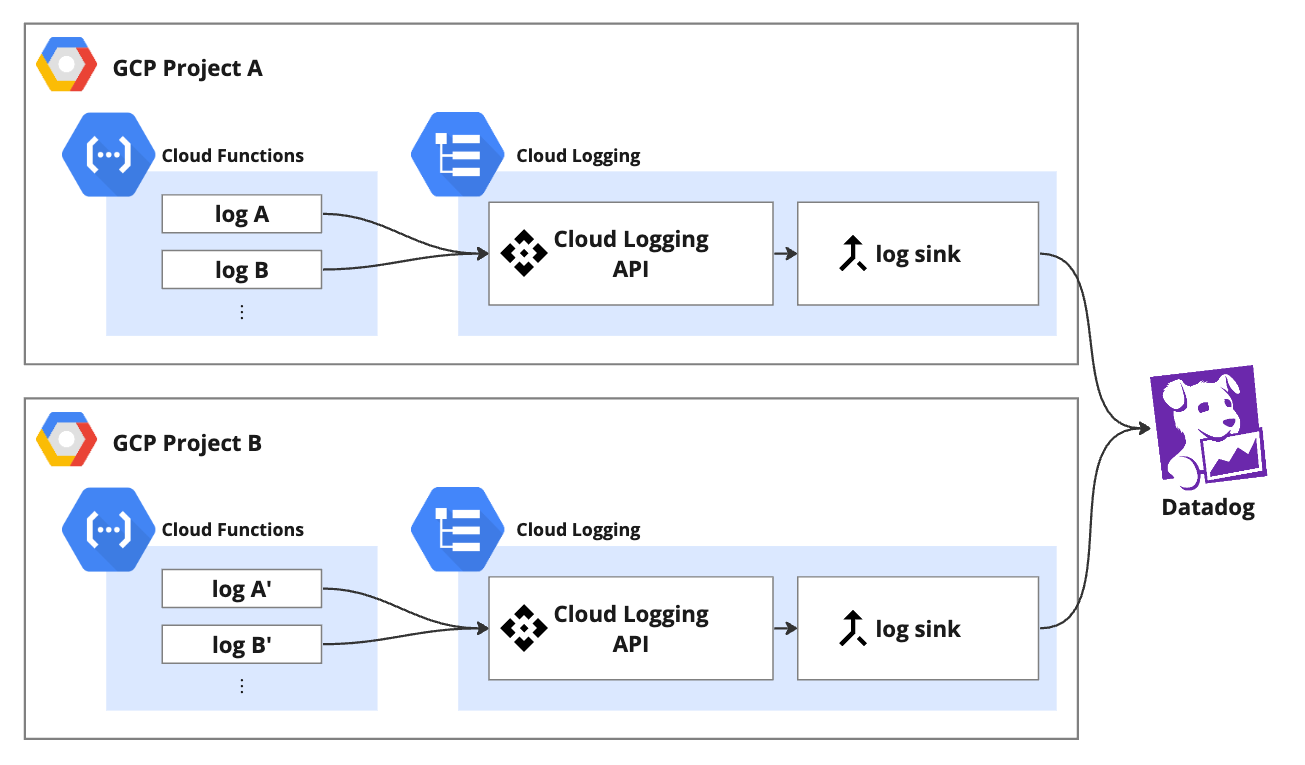
- 現在我々が構築しているデータパイプラインは、Cloud Functions上で稼働しており、アプリケーションのログはCloud Loggingに転送されます。
- Cloud Loggingに転送されたログは、Log RouterによってDatadogに転送され、可視化されます。
ロギングの実装
続いて、ロギングの実装方法について説明します。なお、本記事では、Pythonで実装した事例を元に説明します。
フォーマッタの設定
最初に、フォーマッタの設定について説明します。 フォーマッタは、出力されるログの形式を定義するものです。 今回のログの出力形式の要件としては、以下のようなものがありました。
- ログの出力形式はjson形式であること
- ログの出力時刻、ログレベル、ログの種類及びメッセージがログに含まれていること
- ログによって追加の情報を付加したい場合、paramsというkeyにjson型で追加できること
このような要件を満たすために、python-json-loggerというモジュールを用いて、 以下のようなフォーマッタを実装しました。 python-json-loggerモジュールは、json形式でログを比較的容易に出力するためのモジュールです。 同様のモジュールとして、jsonformatterがありますが、 こちらは記事執筆時点で最終リリースから1年以上更新されていないため、今回はpython-json-loggerモジュールを採用しました。 下記はアプリケーションログのフォーマッタの実装例であり、システムログのフォーマッタも同様に実装しております。
import os from datetime import datetime from pythonjsonlogger import jsonlogger from dateutil import tz class CustomApplicationLogFormatter(jsonlogger.JsonFormatter): def __init__(self, log_subcategory: str, *args, **kwargs) -> None: super().__init__(*args, **kwargs) self.log_subcategory = log_subcategory def parse(self) -> list[str]: """json attributeのkeyを定義する""" return ["ts", "log_category", "log_subcategory", "severity", "hoge1", ..., "message", "params"] def add_fields(self, log_record, record, message_dict) -> None: """ログに追加する情報を定義する""" super().add_fields(log_record, record, message_dict) log_record["ts"] = datetime.now(tz.gettz("Asia/Tokyo")).isoformat(timespec="microseconds") log_record["log_category"] = "application_log" log_record["log_subcategory"] = self.log_subcategory log_record["severity"] = record.levelname log_record["hoge1"] = os.getenv("HOGE_1") log_record["message"] = record.getMessage() def process_log_record(self, log_record: dict) -> dict: """ログレコードを整形する""" # logger.info等の引数にextraが指定された場合、ログのparams attributesに追加する params = dict() for key in log_record.keys(): if key not in self.parse(): params[key] = log_record.get(key) if len(params) > 0: log_record["params"] = params # parseで定義したattributesのみ残す processed_log_record = dict() for key in self.parse(): processed_log_record[key] = log_record.get(key) return processed_log_record
ハンドラの設定
次に、ハンドラの設定について説明します。 ハンドラは、ログの出力先を定義するものです。 Python標準のloggingモジュールには、多くのハンドラが用意されています。 今回は、ログを標準出力として出力したかったため、StreamHandlerを用いました。
ロガーの設定
最後に、ロガーの設定について説明します。
ロガーは、アプリケーションコードがログを生成して最終的にログを出力するために用いるインスタンスです。
ロガーは、loggingモジュールのgetLoggerメソッドを用いて取得することができます。
最終的に、ロガーを生成し、ハンドラとフォーマッタを設定するような関数を作成しました。
from logging import INFO, StreamHandler, getLogger def set_application_logger(name: str, log_subcategory: str = "operation_log") -> None: """application log用のLoggerを生成する""" formatter = CustomApplicationLogFormatter(log_subcategory) handler = StreamHandler() handler.setFormatter(formatter) logger = getLogger(name) logger.setLevel(INFO) logger.addHandler(handler) logger.propagate = False
ロギングの実装例
最後に、ロギングの実装例を示します。 今回は、Cloud Functions上で稼働しているアプリケーションの処理の一部を抜粋しました。
まず、ロガーを生成するために、__init__.pyに以下のようなコードを追加します。
__init__.pyにロガーの設定を記述することで、そのディレクトリに含まれるすべてのファイルで同一のロガーの設定を利用することができます。
from .logger import set_application_logger set_application_logger(__name__, log_subcategory="data_access_log")
次に、アプリケーションコードに以下のようなコードを追加します。
from logging import getLogger from google.cloud import storage logger = getLogger(__name__) client = storage.Client() bucket_name = "hoge-bucket" try: bucket = client.get_bucket(bucket_name) except Exception as e: logger.critical( e, extra={ "bucket_name": bucket_name, "access_target": "GCS", }, ) raise e logger.info(f"Bucket gs://{bucket_name} fetched.", extra={"bucket_name": bucket_name, "access_target": "GCS"})
上記のように、ロギングの実装を行うことで、以下のようなログが出力されるようになります。
{ "ts": "2023-12-08T09:13:07.123456+09:00", "log_category": "application_log", "log_subcategory": "data_access_log", "severity": "CRITICAL", "hoge1": "hoge1", "message": "google.cloud.exceptions.NotFound: 404 GET https://storage.googleapis.com/storage/v1/b/hoge-bucket?projection=noAcl: Not Found", "params": { "bucket_name": "hoge-bucket", "access_target": "GCS" } }
実運用時の使用感と課題
上記のロギング実装をシステムに導入し、datadogでログを確認すると、以下のようなログが出力されていることが確認できました。
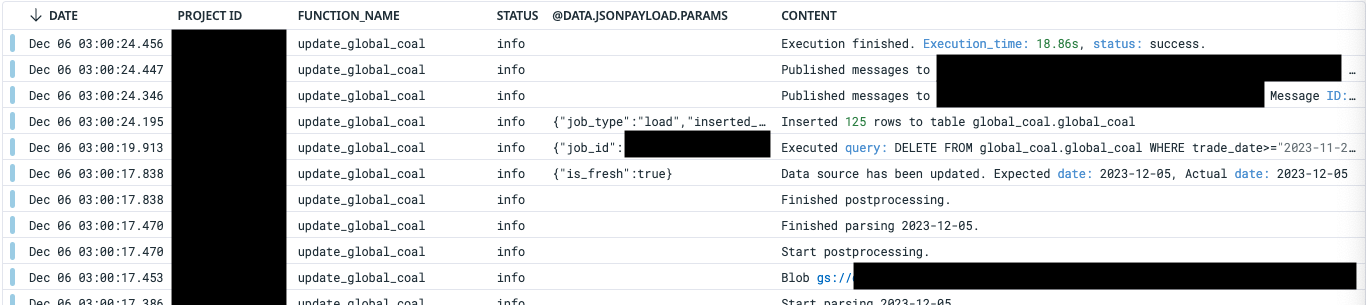
実際に、ログを出力することで、以下のような効果がありました。
- データパイプラインの処理の進捗を把握することが今まで以上にできるようになりました。
- エラーが発生した際に、Traceback情報だけでは原因を特定することが難しいことがあります。より詳細かつ監視者にとってわかりやすいエラーログを出力することで、エラーの原因を特定することが容易になりました。
一方で、以下のような課題がありました。
ログの出力行数が想定より多いパイプラインがある
- 現在の処理ではGCSに複数回アクセスするものもあり、アクセスの度にログが複数回出力されてしまいます。
- 今後は、このような処理については、ログの出力を一度にまとめるような処理を実装することで、ログの出力本数を減らすことができると考えています。
取得したかったメトリクスが取れない場合がある
- 現行のCloud Functionsで稼働しているデータパイプラインでは、リトライ回数等のメトリクスを取得することができませんでした。
- 今後は、データパイプラインの稼働時のアーキテクチャを変更するというプロジェクトが進行中で、その際にメトリクスを取得できるようにする予定です。
まとめと今後の展望
今回のロギング設計・実装手法により、データパイプラインのobservabilityを向上させることに成功しました。 observabilityを向上させることで、トラブル時にも原因の見通しが立ちやすくなりました。 これにより、データ品質の中でも、課題としていた即時性の観点で向上に繋がったと考えております。 今後は、定量的な計測を行い、適切にモニタリングを追加することで、よりデータの品質を向上させたいと考えております。
おわりに
本記事では、データ品質の向上を目標に、ロギングを適切に設計・実装する手法をご紹介しました。
ロギングはデータ品質向上のための第一歩であり、これからも発生した課題に対処したり、新たにSLIを設定する等、データ品質向上のための取り組みを継続していきたいと考えております。 機会があれば、データ品質の向上に向けた他の取り組みについても記事にしたいと考えております。
データプラットフォームデスクでは、巨大なマーケットを支えるデータ基盤を一緒に構築する仲間を募集しています。興味のある方は、ぜひ以下のリンクからご応募ください!
明日以降の enechain Advent Calendar 2023 の記事もご期待ください!