
この記事はenechain Advent Calendar 2025の11日目の記事です。
はじめに
enechainのデータ基盤チームでエンジニアをしている菱沼です。
本記事では、複数のドメインチームが持つ独自のロジックを、依存関係を保ちながら処理するデータパイプラインの構築を実践した例をご紹介します。
具体的なアーキテクチャパターン選定の経緯や、Argo Workflows上での実装内容、そして実際の運用において得られた知見を交えて解説します。 ぜひ最後までご覧ください!
背景
enechainのバッチ処理のデータパイプラインは、そのほとんどがArgo Workflows上で構築されています。 また、データ基盤チームがデータの抽出・整備し、データサイエンスチームが分析・推計処理するという役割分担で構築・運用しています。
従来の社内のデータフローでは、「データ基盤チーム → データサイエンスチーム → 利用者」という流れでデータが処理されていました。 今回新たに、データサイエンスチームによる推計処理後に再度データ基盤チームでの加工を必要とする要件が発生しました。
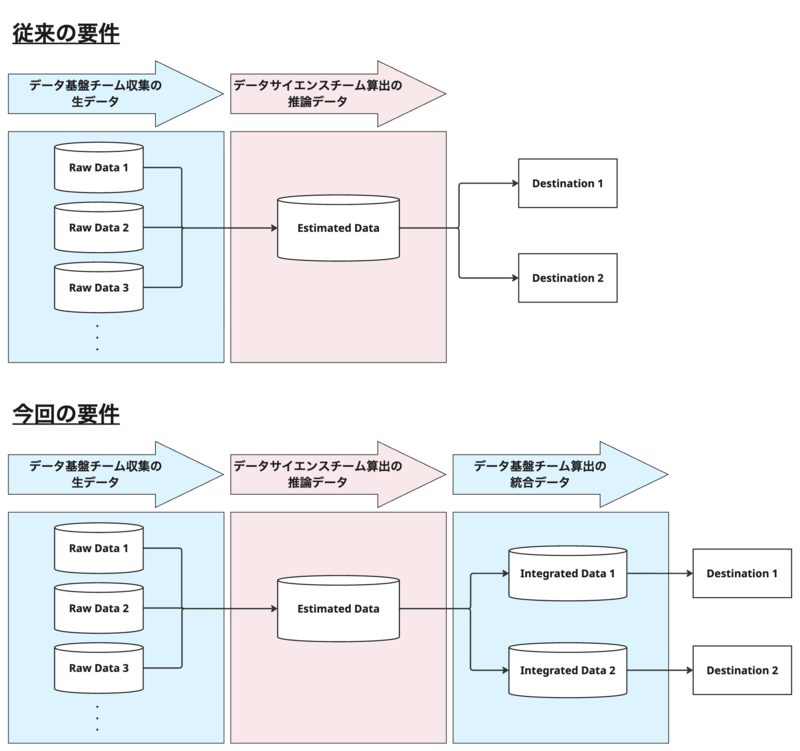
また、ソースとなるデータが更新されたら速やかに下流のデータまで更新し、最終的な利用先まで届ける必要があります。
これらの要件を満たすため、以下の2つの側面から従来の運用フローを見直す必要がありました。
1. 他チーム管理ロジックへの依存
最終的な統合データのオーナーシップはデータ基盤チームにありますが、その生成にはデータサイエンスチームのロジックが不可欠です。 他チームが管理するロジックへの強い依存が発生する中で、いかに互いの責任領域を侵さずに接続するかが問われました。
2. 開発サイクルの相違
一般的に、データの安定供給を目的とするETL処理と、精度向上を目指して頻繁に改善される推計処理では、開発サイクルや変更頻度が異なります。 これらを安易に結合すると基盤側の安定性が損なわれ、逆に完全に切り離すとデータの整合性や順序保証が難しくなります。 異なる開発サイクルの処理を、いかに矛盾なく連携させるかの設計が必要でした。
この構造により、「複数のドメインチームが持つ独自のロジックや依存関係を、どのようにオーケストレーションするか?」という課題を解決する必要が出てきました。
アーキテクチャパターンの検討
チーム間の依存関係を解決するために、何をインターフェースとするかという観点で以下の4パターンを検討しました。
1. ライブラリ共有パターン (Shared Library)
- 仕組み: ロジックをPythonライブラリとして提供し、コードレベルでimportして利用する方式。
- メリット: 実装コストが最も低く、コードの再利用性が高い。
- デメリット: 結合度が強すぎる。チーム間で依存ライブラリのバージョン競合が発生し、基盤チームのデプロイサイクルが他チームの開発状況に引きずられるリスクがある。
2. テンプレート参照パターン (WorkflowTemplate Reference)
- 仕組み: ロジックをArgoのWorkflowTemplateとして登録し、YAML設定レベルでtemplateRefを用いて呼び出す方式。
- メリット: K8sネイティブな機能であり、ArgoのUI上での可視性が高い。
- デメリット: マルチテナント環境下での他のNamespace参照時に権限管理が複雑化する。また、テンプレートのパラメータ定義変更が呼び出し元へ即座に影響するため、運用上の独立性が低い。
3. コンテナインターフェースパターン (Container Interface)
- 仕組み: ロジックを「入出力を定義したDockerイメージ」として提供し、Argoの単一DAG内でタスクとして順序実行する方式。
- メリット: コンテナ内がブラックボックス化され、言語やライブラリの自由度が保たれる。また、Argoが実行順序を管理するため制御が確実である。
- デメリット: ファイルパスや環境変数などの入出力のインターフェース契約を厳密に定義する必要がある。
4. イベント駆動パターン (Event-Driven)
- 仕組み: 互いのワークフローを完全に独立させ、Pub/Sub等のイベントメッセージを介して連鎖させる方式。
- メリット: 最も疎結合であり、各チームが完全に独立してデプロイできる。
- デメリット: 処理が分断されるため、可観測性が犠牲になる。一連のパイプラインとしての実行状況の追跡や、障害発生時の再実行フローが複雑化する。
各方式の特徴を以下の表にまとめました。
| 方式 | インターフェース | 環境の独立性 | 順序の制御性 | 可観測性 |
|---|---|---|---|---|
| 1. ライブラリ共有 | Python Code | × | ◎ | ◎ |
| 2. テンプレート参照 | YAML | △ | ◎ | ○ |
| 3. コンテナ I/F | Docker Image | ◎ | ◎ | ○ |
| 4. イベント駆動 | Message / Event | ◎ | △ | △ |
比較検討の結果、環境の独立性と順序の制御性、可観測性のバランスが最も良い 「3. コンテナインターフェースパターン」 を採用しました。
採用に至った主な理由は以下の通りです。
- 開発サイクルの相違を「環境の独立性」で吸収
- 変更頻度の高い推計ロジックをコンテナ内に閉じることで、安定稼働が求められるETLへの影響を遮断しました。
- オーナーシップの分散を「責任分界点」として定義
- 「コンテナの中身」はデータサイエンスチーム、「実行フロー」はデータ基盤チーム、と管理領域を明確に分離しました。インターフェースさえ守れば、基盤チームが他チームのドメインコードを管理する必要がなくなります。
- マルチテナント環境への適合
- 他チームのK8sリソースを直接参照する複雑な権限設計を避け、シンプルなイメージ参照で完結させるため。
実装
ワークフロー実装
1. データサイエンスチームのimageを参照するWorkflow Template
まず、データサイエンスチームが提供するDockerイメージを利用するためのテンプレートを以下のように作成しました。
apiVersion: argoproj.io/v1alpha1 kind: WorkflowTemplate metadata: name: task-template-ref spec: templates: - name: task-template-science serviceAccountName: data-science-argo-workflow inputs: parameters: - name: target_module container: # データサイエンスチームのイメージを参照 image: asia-docker.pkg.dev/shared-registry/data-science/science-app command: [python, -O, -m] args: - science_app.{{inputs.parameters.target_module}} env: - name: EXEC_DATE value: '{{workflow.parameters.exec_date}}'
2. DAGでの依存関係定義
次に、データ基盤チームとデータサイエンスチームのタスクを統合するDAGを以下のように定義しました。
apiVersion: argoproj.io/v1alpha1 kind: WorkflowTemplate metadata: name: cross-team-workflow spec: entrypoint: main templates: - name: main inputs: parameters: - name: exec_date dag: tasks: # Step 1: データ抽出(データ基盤チームのロジック) - name: extract-data templateRef: name: task-template-ref template: task-template arguments: parameters: - name: target_module value: platform_data.extract # Step 2: 推計処理(データサイエンスチームのロジック) - name: transform-data depends: extract-data.Succeeded templateRef: name: task-template-ref-science # データサイエンスチーム用テンプレート template: task-template-science arguments: parameters: - name: target_module value: science_estimation.transform # Step 3: データ統合(データ基盤チームのロジック) - name: aggregate-data depends: transform-data.Succeeded templateRef: name: task-template-ref template: task-template arguments: parameters: - name: target_module value: platform_data.aggregate
3. Kustomizationリソースでのイメージバージョン管理
データ基盤チームとデータサイエンスチームの両方のイメージバージョンを、Kustomizationで一元管理しています:
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization namespace: data-platform-prod images: # データ基盤チーム管理のイメージ - name: asia-docker.pkg.dev/shared-registry/data-platform/platform-app newName: asia-docker.pkg.dev/shared-registry/data-platform/platform-app newTag: v1.0.1 # データサイエンスチーム管理のイメージ - name: asia-docker.pkg.dev/shared-registry/data-science/science-app newName: asia-docker.pkg.dev/shared-registry/data-science/science-app newTag: v2.3.0 # データサイエンスチームがリリースしたバージョンを指定
権限設定
KSAの作成
同一DAG内でも、データ基盤チームとデータサイエンスチームでは読み書きするリソースが異なるため、それぞれ専用のKSA(Kubernetes Service Account)を作成しました。 以下はデータサイエンスチーム用のService Accountの例です。
apiVersion: v1 kind: ServiceAccount metadata: name: data-science-argo-workflow annotations: iam.gke.io/gcp-service-account: data-science-job-argo@platform-project.iam.gserviceaccount.com
Terraformによる権限管理
GSA(Google Service Account)の作成、Workload Identityの設定、BigQueryデータセットへのアクセス権限は、すべてTerraformで管理しています。 Config Connectorを使うとKubernetes上のYAMLマニフェストとTerraformの両方でGoogle Cloudリソースを管理することになり、管理場所が散らばってしまいます。 よって、ここではGoogle Cloudリソースの管理は一元的にTerraformで行う方針としました。
# GSAの作成 resource "google_service_account" "data_science_argo" { account_id = "data-science-argo-workflow" display_name = "Data Science Argo Workflow Service Account" project = "platform-project" } # Workload Identityの設定 resource "google_service_account_iam_member" "workload_identity" { service_account_id = google_service_account.data_science_argo.name role = "roles/iam.workloadIdentityUser" member = "serviceAccount:${var.project_id}.svc.id.goog[data-platform-prod/data-science-argo-workflow]" } # BigQueryデータセットへのアクセス権限付与 # データ基盤チームのデータセットに対する読み取り権限 resource "google_bigquery_dataset_iam_member" "platform_data_reader" { dataset_id = "platform_dataset" project = "platform-project" role = "roles/bigquery.dataViewer" member = "serviceAccount:${google_service_account.data_science_argo.email}" } # データサイエンスチームのデータセットに対する書き込み権限 resource "google_bigquery_dataset_iam_member" "science_data_writer" { dataset_id = "science_dataset" project = "science-project" role = "roles/bigquery.dataEditor" member = "serviceAccount:${google_service_account.data_science_argo.email}" }
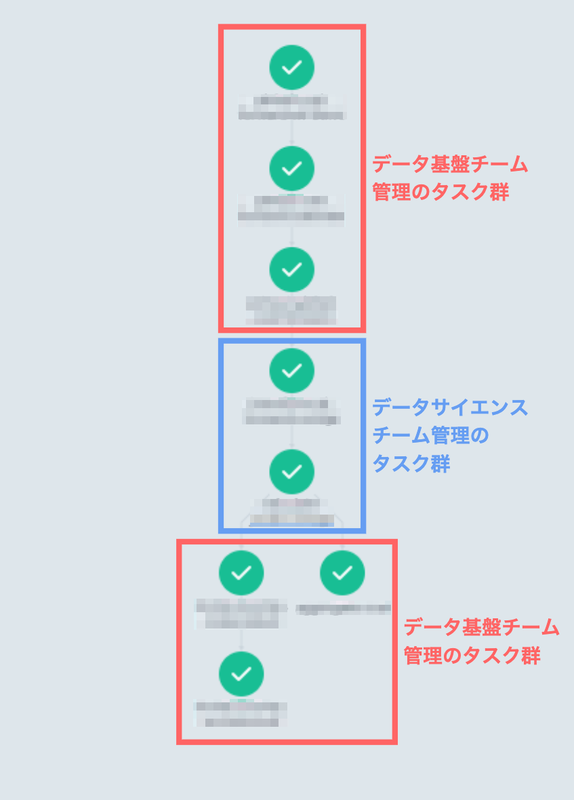
上記のようなワークフローと権限実装により、以下のようにArgo Workflowが正常に動作しました。
運用
デプロイ運用
データサイエンスチームが新しい計算モデルをリリースした際の運用フローは、以下のとおりです。
| 作業内容 | データサイエンスチームのやること | データ基盤チームのやること |
|---|---|---|
| imageのtag version変更 | KustomizationのnewTagを変更するPRを作成&データ基盤チームにレビュー依頼 | レビュー |
| デプロイスケジュール調整 | 両チームでスケジュールを調整 | 両チームでスケジュールを調整 |
| デプロイ | - | 環境順にデプロイ |
データサイエンスチームの作業はイメージタグの変更のみで、非常にシンプルな運用となっています。
Container Interfaceパターンの採用により、データサイエンスチームは独自の開発サイクルでイメージをリリースでき、作業間の依存関係も最小限に抑えられる簡潔な運用が実現できています。
アラート運用
ワークフロー失敗時にはどのタスクが失敗したかに関係なく、両チームにSlackメンションを送信するアラートを設定しています。 外部データソースの遅延など、データサイエンスチーム側に起因しないエラーでもSlackメンションを飛ばすことがあります。 ただし、データサイエンス側のデータが生成されていなかったりデータサービスに連携されていないことに気づかないことを防ぐため、ワークフロー全体の失敗時にアラートを送信する設計としています。
今後の展望
Container Interfaceパターンの導入により、チーム間連携の基盤は整いました。 現在の運用では大きな課題はありませんが、今後このパターンを活用したワークフローが増加した際に備え、以下のような改善を検討しています。
アラート運用の効率化
現在は両チームへ一律にアラートを送信する運用で問題なく回っていますが、失敗したタスクから適切なメンション先を特定し、原因チームにのみメンションする仕組みの導入を検討しています。 これにより、障害発生時の初動対応がより迅速になり、関係のないチームへの不要な通知を削減できると考えています。
ログ運用の標準化
現状ではログフォーマットが統一されていません。 チーム間で共通のフォーマットを採用することで、トラブルシューティングがより楽になり、横断的な分析が可能になります。
おわりに
今回は、Container Interfaceパターンを用いて、複数チーム間の依存関係を持つパイプラインをArgo Workflowsで実装した事例について紹介しました。
「コンテナによる環境の分離」と「DAGによる順序の制御」を組み合わせたこのアーキテクチャにより、チーム間の独立性を保ちつつ、データ基盤として求められる堅牢な整合性を両立できました。 今後もこのような設計パターンを活用し、異なるドメインがシームレスに連携するスケーラブルなデータ基盤を構築していきます。
enechainでは、巨大なマーケットを支えるデータ基盤を一緒に構築する仲間を募集しています。 興味のある方は、ぜひ以下のリンクからご応募ください!