

この記事は enechain Advent Calendar 2023 の7日目の記事です。 昨日は @K-Fujimura の Slack Boltで実現するHuman in the Loop でした。
はじめに
enechain データプラットフォームデスク エンジニアリングマネジャーの藤木です。
enechainは電力卸売市場を核としたエネルギー取引のマーケットプレイスを運営しています。 私の所属するデータプラットフォームデスクは全社に向けたログ基盤の提供や、 eCompass と呼ばれる「エネルギー関連データ提供SaaS」の裏側のデータ収集、集計を担っています。
ログ基盤に関しては以下の記事に記載されておりますのでこちらもぜひ参照ください。 techblog.enechain.com
enechainが提供するeCompass
私は9月にenechainに入社したばかりなのですが、今まで比較的規模の大きな会社で「データプラットフォームが存在することが前提の環境」でデータエンジニアやエンジニアリングマネジャーとして約10年程働いてきました。
そんな中で今回初めてアーリーステージのスタートアップのデータプラットフォームチームで働くことになりました。 弊社の事業環境は少し特殊性があるため同ステージの会社全般に当てはまるという話ではないかもしれませんが、入社して3ヶ月で感じたことを書いていきたいと思います。 (タイトルの「データ基盤」は少し広い解釈を持つ言葉だと思いますが、ここではデータエンジニアが構築するデータパイプラインなどを中心とした「システムとしてのデータパイプライン」を指しています)
enechainのデータを取り巻く環境について
弊社で扱うデータは
- 内製プロダクトから産まれるデータ
- 外部から購入/取得を行っているエネルギーに関する様々なデータ
が中心です。
現状のプロダクトデータに関しては、他社様のBtoC事業や顧客数の多いBtoB事業と比較するとそこまでデータ量は多くありません。 現在展開しているプロダクトでは契約会員数は電力会社様を中心に約200社程度の規模となっております。 ただ、エネルギー市場全体の金額的規模は非常に大きく、弊社が運営するマーケットの累計取扱高は1兆円を超えており、さらに100兆円を超えるマーケットを作ることを目指しております。また、今後の事業展開ではより多くのお客様に向けたプロダクトの展開もあり得ます。
プロダクトの数、必要なデータ量は着実に増えていっており、冒頭で紹介したログ基盤を提供し始めたようにデータ基盤の必要性は高まってきている状態です。
3ヶ月で感じた今までとの違い
ここから本題のこの3ヶ月感で感じた前までとの感覚の違いについて書いていきたいと思います。
「データエンジニアがデータプラットフォームを構築する」意味
はじめに「データエンジニアがデータプラットフォームを構築する意味」について、これまでとの違いを感じている点を書いてみたいと思います。 データプラットフォームの構築の目的はもちろんデータ活用に他ならないと思いますが、データエンジニアがプラットフォームとしてそれを構築するというところの意味合いに関しては(メガベンチャーvsスタートアップというより昔と今という観点も含めて)少し変わってきているかもしれないと感じました。
以下に2つの観点を書いてみたいと思います。
1.専門性を集約し、車輪の再発明を防ぎ、効率化を図る
元々データエンジニアがプラットフォームを作るべきだという背景としてこの考え方が個人的には中心にありました。 様々な場所に散らばるデータを横断的に活用したいと考えた時に、データをDataLake/DWHなどに集約するために各データソース毎に専用の仕組みを構築していこうとすると、以下のような問題が発生します。
- 専門性の異なる人達が、データを扱うために各々学習コストを払う非効率性
- 同じような仕組みが複数出来上がってしまう非効率性(車輪の再発明)
そのため、専門性を持ったチームがそれを一手に引き受け、共通の仕組みを作ることによって全体の効率化(=コスト削減)を図ることが重要です。
これは、事業規模の拡大に伴ってプロダクトや社外とのデータ連携の増加、また活用したいデータの多様化などによってプラットフォームで扱われるデータソースの数が増加するのと比例して効果が高まっていきます。
ただ、昨今はデータを一旦活用できるようにする(ここではBigQueryのようなDWHやAthenaのようなクエリエンジン等でSQLで参照できるようにすることとします)ということだけにフォーカスすれば、DWHも簡単に利用が開始でき、そこにデータを集約するという面もクラウド機能の進化やETL SaaSの台頭により昔と比較してかなり敷居が下がっています。
アーリーステージのスタートアップでは、データソースの種類や利用者、ユースケースが少ない状況が多く、上記の通りデータエンジニアがいない場合でも比較的容易にデータ活用環境構築が実現できるケースもあり、データプラットフォーム構築の必然性はそこまで高くない部分もあります。 弊社の中でもデータプラットフォームが存在しなくても個別のデータ活用自体は一定進んでいた面がありました。
ではわざわざデータエンジニアが専門性を持ってプラットフォームを作る、という必要は今のフェーズにおいてはないのか?というとそうではないと思っています。
2. 早めに仕組みとしての「マネジメントポイント」をつくることの重要性
もう一つ重要な点としてあげたいのは、データマネジメントに関する様々な仕組みやルールを注入するためのポイントをつくる、という点です。
データ界隈で働く方たちには既に浸透している考え方ですが、データマネジメントとはデータを資産として捉えて適切に管理し、安全かつ効率的にデータの価値を引き出すという取り組みです。
データマネジメントを横断的に行う際には、プラットフォームが重要な役割を果たします。
例えばDWH上でとあるデータのユースケースがあり、いくつかのデータを横断的に活用するかつ社外にも影響のある重要なものだったとします。このケースではデータの品質が重要ですが、DWHのデータの品質はそのデータを運んでくる各パイプラインの仕組みに依存する部分が多いです。 その仕組みがバラバラな中ではデータ品質の計測や、計測の結果見つかった問題点の対処をそれぞれで行う必要があり、大きな手間となります。 データを収集している基盤が同じ仕組みであれば、統一的な観点での品質のモニタリングと、その後の改善サイクルを回すことができます。
また、お客様から預かる重要なデータをきちんと取り扱うために、データセキュリティの面で適切なアクセス管理をしたいと考えた時にも、バラバラなパイプラインで様々な場所に思想なく散らばったDWH上のデータは、どこに何があるのかも管理できずに同じデータが複数の場所に散らばるなどして一貫性も保てず、正しいアクセスコントロールを行うことも難しいでしょう。 データの収集の仕組みが統一的であれば、こういった管理も非常にしやすくなります。
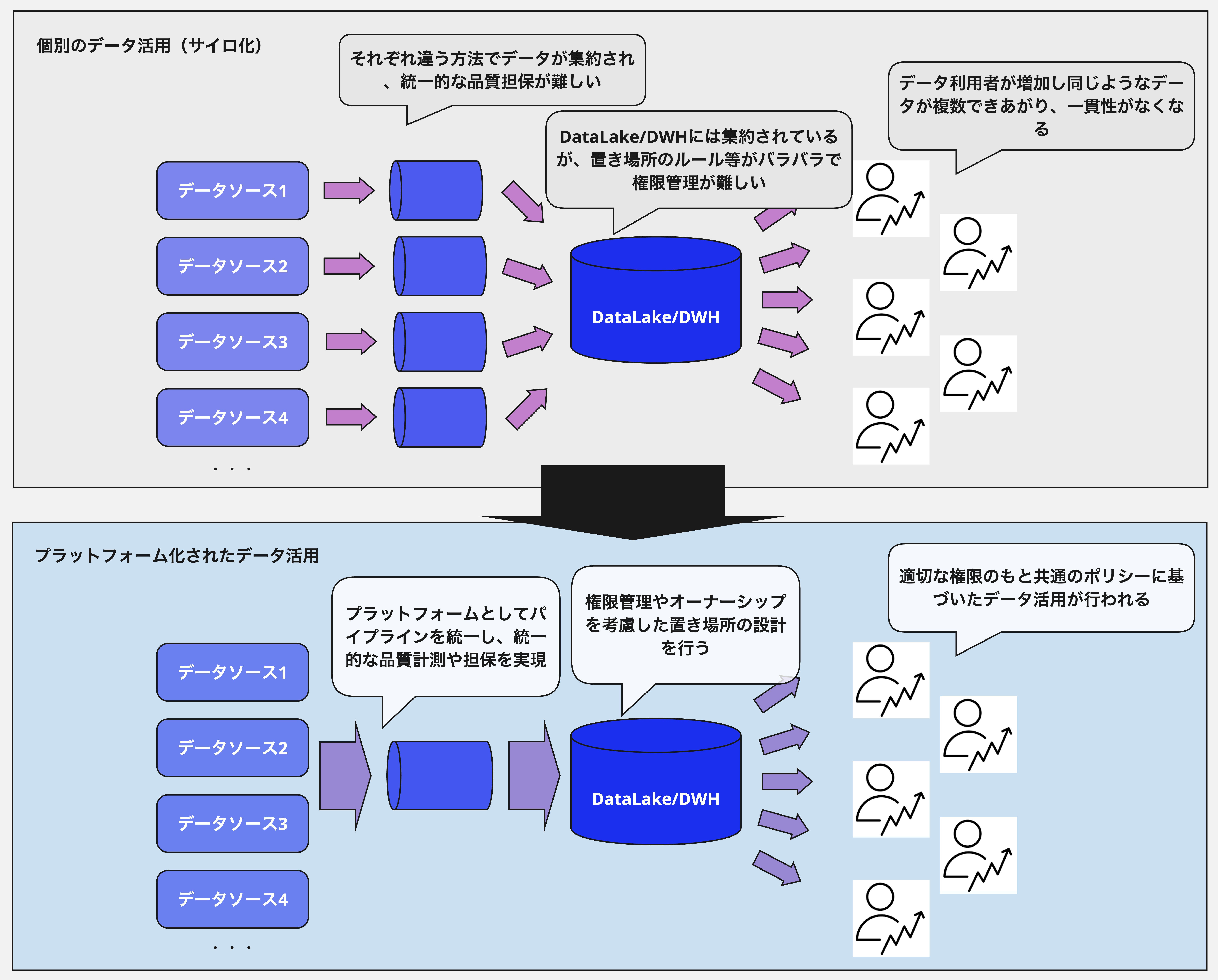
これはほんの数例ですが、その他にもデータマネジメントに関する様々な取り組みのやりやすさにプラットフォーム化されているかどうかという観点は大きく起因してくると思います。
データ活用の敷居が下がっているという前述の話との裏返しですが、比較的簡単にできてしまうがゆえにサイロ化したデータ活用が横行して逆にマネジメント・ガバナンスが置いてきぼりになるケースは発生のリスクが高まっている気もしております。(もちろん昔からありましたが…)
また、サイロ化した状態で拡大したデータ活用において、あとから全社統一的なデータマネジメントを行うことはその取組の開始が遅くなればなるほど非常に難易度が高まっていきます。
弊社で目指しているエネルギーにおける公平公正なマーケットをつくる、というミッションでも、データマネジメントは非常に重要なポイントとなります。 そういった意味でも、早いフェーズからデータエンジニアが専門性を持ってデータプラットフォームを構築し、マネジメントポイントを作ることに意味はあるのではないかと思います。
データプラットフォームチームで果たすべき役割
1点目は仕組みとしてのプラットフォームという観点でのお話でしたが、現在のフェーズにおいてのデータプラットフォームチームとしての役割という観点も書いてみたいと思います。
悪い意味でのプラットフォーム思考に陥りすぎないように
規模の大きな会社におけるデータプラットフォームチームの役割として、あくまで全プロダクト共通部分を作成し、それを広く導入することによって効率化、最適化を図ることに注力をする、逆説的にいえば特定のサービスやプロダクト、ユースケース固有のロジック部分は請け負うべきではない=「ビジネスロジックを排除する」を徹底するのが、ベストプラクティスだという印象がありました。
これは個別のビジネスロジックにプラットフォームが関わり始めてしまうと、各プロダクトにおける改善のスピードにプラットフォームのリソースがボトルネックとなる危険性があるからです。
今もその考えが変わっているわけではなく、実際に状況によって正しいケースもあると思っておりますが、スタートアップのスピード感に対してこれにこだわりすぎてしまうとチームとして価値が出せないケースが往々にしてあると感じます。 大きい企業の中ではチーム毎の役割が明確化、最適化されているケースが多いですが、チームが少なく動きの早いスタートアップの中ではそのあたりも柔軟に取り組む必要があると思います。
なので、このフェーズにおいては特定の要件やユースケースに対応する個別の成果創出 + プラットフォーム構築を並行してバランスよくやっていくことがチームの役割としては重要だと感じています。 ただ、システム設計の面でいえば、個別の機能については明確にプラットフォームから切り出してアーキテクチャを考えることも重要です。 個別の機能がプラットフォームと同化して密結合になってしまうと、将来的に大きな負債となって自分たちのもとに返ってくる可能性が高くなります。
チームの立ち上げについて
そもそもチームを立ち上げる、という面においてもどうやって立ち上げればよいのかという悩みも出てくることが多いのではないかと思います。
いつ?というタイミングについては各社の事情によって変わってくる部分もあるのかなと思いますので一概には言えないところはあると思いますが、共通して言えるのはスタートアップで少ない人数でかなり早いスピード感でプロダクトを世に出していかなければいけない中で、腰を据えてプラットフォームを作るために人を寄せ、チームを作り、もしくは人を雇い、というのはかなり難易度が高いのではないか?というところです。
タイミングではないですが「立ち上げ方」という観点においてはいきなり「ゼロから立ち上げる」という以外にも選択肢があるのではないかと思います。
弊社のデータプラットフォームデスクもゼロからの立ち上げではなく前身のチームが存在しており、それは冒頭で紹介した eCompass というデータプロダクトのためのデータ収集と集計を行っていたチームでした。 その後、全社としてのデータ整備のニーズが高まってきた段階で全社のデータプラットフォーム整備も視野に入れたチームとして変わりました。
立ち上げ時に上記のようなリソースの難しい調整やなぜ今?という観点に(場合によっては専門家もいない中で)机上で時間を使いすぎてしまうよりかは、個別の要件を対応するチームの延長線としてのプラットフォームチーム化、というシナリオもあるのではないかと思います。(既存リソースで立ち上げられるという事もあり難易度も下がりますし、チームという箱があればその後の採用もやりやすくなると思います)
最後に
アーリーステージのスタートアップにおいても、データ活用のサイロ化には注意してデータプラットフォームの整備を検討することの必要性は一定あるのではないかと思いますが、スタートアップらしくセクショナリズムを持たずに事業貢献を皆で意識して動いていくバランスが重要なのかなと思いました。
今回は入社まもないこともあり抽象的な話ばかりになってしまいましたが、次回はなにかまた具体的な仕組みの導入事例などかけたらと思います。
明日は同じチームの @T-Hishinuma0821 による記事になります!
データプラットフォームデスクでは一緒にこの巨大なマーケットを支えるデータ基盤を作ってくださる方を募集しています。興味を持ってくださった方はぜひ応募していただけますと幸いです!