

はじめに
この記事はenechain Advent Calendar 2025の4日目の記事です。
こんにちは、enechainで統計・機械学習モデルの構築やLLM(大規模言語モデル)の活用推進を担当している@udon_tempuraです。
昨今、Claude Sonnet 4.5やGPT-5.1、Gemini 3.0 Proなど強力なAIモデルが次々と登場し、できることは爆発的に広がっています。 しかし一方で、「AIをうまく使いこなせていない」と感じる場面も少なくありません。 その主要なボトルネックのひとつがコンテキストの欠如です。今回は、Google Meetの録画をGeminiで解析し、AIエージェントが活用できる構造化Markdownを自動生成するという手法で、チーム内の暗黙知を低コストでドキュメント化した取り組みについてお話しします。
対象読者
- Claude CodeなどのAI Coding Agentを導入しているが、期待した精度が出ないと感じている方
- チーム内のドキュメント化が追いつかず、ナレッジが属人化している開発チーム
- マルチモーダルAI (動画解析) の実用的な活用事例を探している方
課題
AIモデル自体の性能は飛躍的に向上していますが、まだまだ期待通りの出力が得られないケースも多くあります。 その原因は多岐にわたりますが、私たちの主な課題は、AIに必要なコンテキストを十分に提供できていないことでした。 コンテキストを与えきれない理由は主に2つあります。
- 情報の散逸: 情報がチャット、コード、Wikiなど様々な場所に散らばっており、AIが(あるいは人間も)探せない。
- 暗黙知の壁: そもそも情報として明文化されておらず、個々人の頭の中にしか存在しない「暗黙知」になっている。
特に厄介なのが後者です。 「なぜこの機械学習モデルを採用したのか」「なぜ今の実装になっているのか」「どういうビジネス的な背景・インパクトを考慮したのか」といった文脈は、コードだけからは読み取れません。 これらはナレッジシェアが難しく、AIに入力するためのドキュメント作成も非常にコストがかかるため、AI活用の大きな障壁となっていました。
解決案
そこで私たちは、執筆当時の最新モデルであったGemini 2.5 Proの強力なマルチモーダル性能を活かし、手間をかけずに暗黙知をドキュメント化するアプローチを導入しました。 具体的には以下の戦略をとりました。
- 書くのではなく、喋る: ドキュメントをゼロから書くのは面倒だが、ミーティングで話すのは比較的容易である点を利用する。
- 動画からMarkdownへ: Google Meetの録画データをGeminiに入力し、構造化されたMarkdownドキュメントを生成させる。
- レビューによる品質の担保: 生成されたドキュメントをGitHubのPull Requestとしてチームでレビューして品質を担保する。
なぜ動画とGeminiなのか
弊社における従来のドキュメント作成の大きな課題のひとつは、ゼロから文章を書き起こす心理的ハードルの高さにありました。 どこまで詳しく書くべきか粒度の調整も難しく、さらに一度書いても更新されずに陳腐化してしまうという継続性の課題も抱えていました。
一方、動画を使ったアプローチでは、普段のミーティングと同じ感覚で知識を共有できるため心理的ハードルが大幅に下がります。 会話の中で自然に重要な点が強調され、難しい部分は確認や議論が起きて詳細化されるため、粒度の悩みはありません。 さらに、画面共有でコードや資料を映しながら説明すれば、その映像もGeminiが解釈してくれるため、テキストや音声だけでは伝わりにくい情報も取り込めます。
また、数あるマルチモーダルAIの中でGemini 2.5 Proを選んだのには明確な理由があります。 長時間動画を一度に処理でき、専門用語や技術的な議論も正確に理解する高精度な文脈理解する能力があること、 そしてWeb UIからの動画入力がスムースでPDCAを回しやすいことが決め手でした。
実践:コンテキスト作成のフロー
暗黙知をAI Readableなコンテキストにするため、以下のフローを構築しました。
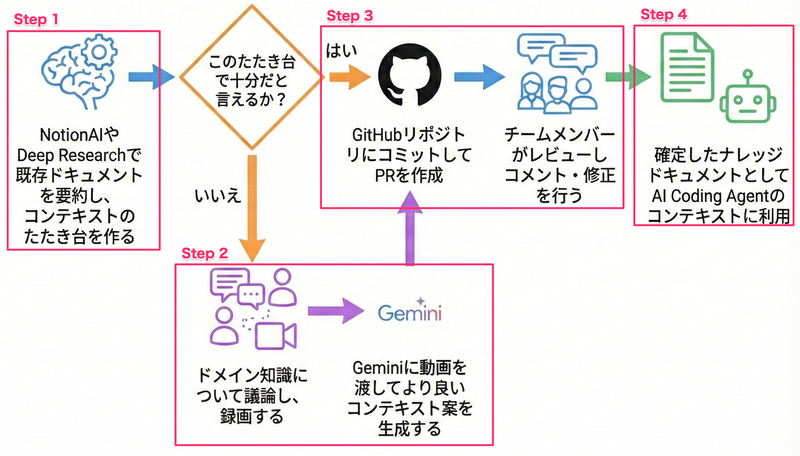
Step 1: Notion AIによる「叩き台」作成
いきなり「さあ喋って」と言っても何を話すべきか迷うことに加えて、既存のドキュメントからの要約でも十分なコンテキストが準備できる場合もあるため、 まずは既存のナレッジベース(Notion)を活用してたたき台を作成します。
Notion AIのDeep Research機能を使うことで、現状のドキュメントから「どのような情報が存在するか」を抽出し、「何を補足して話すべきか」というディスカッション用のアジェンダを自動生成できます。これにより、散在する情報が構造化され、議論の出発点が作成されます。 また、AI生成結果が後述する出力フォーマットに合うように、Notion AIへのプロンプトで指示することで無駄な文章整形作業が少なくなるように工夫しています。
この時点で十分な品質だと判断した場合は、すぐにGitHubのPull Requestを作成します。
Step 2: チームディスカッションと録画、Gemini処理
ディスカッションの実施
作成したたたき台をGoogle Meetで投影しながら、チームメンバーでディスカッションする様子を録画します。
ディスカッションのアジェンダは、Geminiに指示する出力フォーマットと対応させることが重要です。 今回はStep 1にて出力フォーマットに沿った構成でたたき台を作成しているため、そのままアジェンダとして利用しました。 具体的には、以下のような観点で議論を進めます。
- なぜこの実装になったのか(→ ドメイン背景セクション)
- 背景にあるビジネス課題は何か(→ ドメイン背景セクション)
- どのような判断基準で技術選定したのか(→ 前提・仮定セクション)
- 運用上の制約や前提条件(→ 運用セクション)
これにより、以下の効果が得られます。
- 議論の漏れ防止: フォーマットの各セクションに対応する話題が自然とカバーされます。
- Geminiの出力精度向上: 議論の流れがそのままドキュメント構造に反映されるため、Geminiが情報を適切なセクションに振り分けやすくなります。
- レビュー負荷の軽減: 構造が一致していることで、レビュー時の手戻りが減少します。
Geminiによる動画のMarkdown化
録画した動画ファイルをインプットとして、Geminiに処理させました。 ここでは、単なる文字起こしではなく、AIエージェントが読み取りやすいよう構造化されたMarkdownフォーマットへの変換を指示しました。 これにより、動画内で語られた背景や経緯が高い精度でテキスト化されました。
Step 3: GitHubでのチームレビューと品質担保
Geminiで生成されたドキュメントは、そのままでは情報の正確性や網羅性に課題がある場合があります。 そこで、GitHubのPull Requestを活用し、人間が最終的な品質担保を担うプロセスを構築しました。 このプロセスにより、チームの集合知で内容を精査することでハルシネーションの影響を抑制できます。 また、レビュー自体が追加の暗黙知を顕在化させる効果もあります。 さらに、PRの履歴が残るため、どのように知識が進化したかをトレース可能であり、継続的な改善を実現しやすくしています。
Step 4: AIエージェントでの活用
品質が担保されたMarkdownファイルはGitHubリポジトリに配置されているため、Claude Codeなどのエージェントが適宜参照できます。 これにより、AIエージェントはドメイン知識を理解した上でコードレビューや実装提案を行えるようになります。
Geminiでの動画処理の工夫
ここからは、どのようにGeminiを使って動画をMarkdown化したのか、技術的な詳細を解説します。
Geminiプロンプトの設計
単に「動画を要約して」と指示するだけでは、AIエージェントが活用しにくい形式になってしまいます。 そこで、以下の3つの設計方針を採用しました。
- 構造化の徹底: 見出しレベルを統一し、セクションごとに情報を整理
- AIフレンドリーな形式の採用: Markdown formatの採用、専門用語の定義など、明示的な記法を使用
- メタ情報の付与:
情報なし、曖昧な点など情報の信頼性を明示し、レビュー時の注意点を詳細化
メイン処理定義
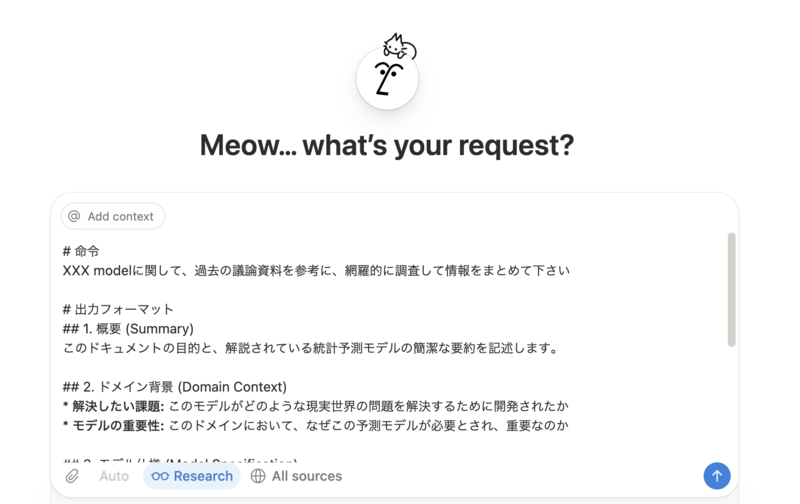
以下は、実際に使用したプロンプトの主要部分です (統計モデリングと電力取引のドメインに特化した例)
# 命令書 あなたは、統計モデルと電力取引、先物取引に精通した第一級の専門家です。 あなたの任務は、動画を分析し、AIモデルやシステムが容易に解釈・利用できる、 構造化された技術ドキュメントを生成することです。 ## 制約条件 * **正確性の重視:** 書き起こしから得られる情報のみに基づき、 推測や不確かな情報の補完は避けてください。 * **専門用語の定義:** 登場する専門用語や略語は、初出時に必ず定義を記述してください。 * **数式の形式:** 数式はすべてLaTeX形式 ($または$$で囲む) で記述してください。 * **構造化:** 出力は必ず以下のMarkdownフォーマットに従ってください。 各セクションが見出しレベル2 (##) で区切り、 内容が不足している場合は「情報なし」と明記してください。 ## 思考プロセスの明示 まず、ドキュメントを生成する前に、動画の内容を分析し、 各セクションにどの情報を割り当てるべきか、思考プロセスを記述してください。 その後、完成したドキュメントを出力してください。 * **ステップ1: 全体像の把握** * この動画が解決しようとしている課題は何か。 * 紹介されている統計予測モデルの名称と種類は何か。 * **ステップ2: 情報の抽出と分類** * 「ドメイン背景」セクションに該当する箇所を特定する。 * 「モデル仕様」に関する部分 (変数、数式、仮定など) を抜き出す。 * **ステップ3: 専門用語と曖昧な点の特定** * 定義が必要な専門用語をリストアップする。 * 動画の説明だけでは不明確な点、矛盾している点をリストアップする。
メイン処理定義の工夫ポイント
- 思考プロセスの明示: 思考プロセスセクションではいきなりドキュメントを生成するのではなく、段階的に分析して精度を向上させています。一般的にThinking modelはプロセス明示が必須でないと言われていますが、今回のケースでは記載したほうが品質の高い出力が得られる傾向がありました。
- 明示的な制約条件:
推測しない、専門用語を定義するなど、AIの行動を明確に規定し、意図しない出力を抑制します。これにより、ディスカッション時に漏れた論点を明確化でき、レビューによる品質担保の促進を狙います。 - ドメイン特化: 統計モデル・電力取引という専門分野を明示し、文脈理解を支援します。
- フォーマットの厳格化: Markdownの見出しレベルやLaTeX形式を指定し、一貫性を担保します。
出力フォーマット定義
詳細な出力フォーマットは以下のように定義しました。
# Document format ## 1. 概要 (Summary) このドキュメントの目的と、解説されている統計予測モデルの簡潔な要約を記述します。 ## 2. ドメイン背景 (Domain Context) * **解決したい課題:** このモデルがどのような現実世界の問題を解決するために開発されたか * **モデルの重要性:** このドメインにおいて、なぜこの予測モデルが必要とされ、重要なのか ## 3. モデル仕様 (Model Specification) * **モデル名:** モデルの正式名称、通称 * **目的変数 (Target Variable):** 予測したい対象の変数 ($y$) を記述 * **説明変数 (Explanatory Variables):** 予測に用いる変数 ($\boldsymbol{x}$) をリスト化 * **数式表現 (Mathematical Formula):** モデルを表現する数式をLaTeXで記述 * **前提・仮定 (Assumptions):** モデルが成立するための前提条件や仮定 ## 4. データ (Data) * **使用データ:** データの種類と出所 * **データ期間・サンプルサイズ:** 学習に使用したデータの範囲 * **前処理 (Preprocessing):** 欠損値処理、標準化、対数変換など (以下、アーキテクチャ、実装と評価、運用、専門用語集、曖昧な点と続く)
このフォーマット定義により、どんな動画を入力しても一貫した構造のドキュメントが生成されます。
自社に適用する際のポイント
上記の出力フォーマットはenechainの統計モデリング・電力取引ドメインに特化した例ですが、他のドメインに適用する際は以下の点を意識してみてください。
- ドメインに合わせたセクション設計: 業務で重要な観点(例:セキュリティ要件、法規制対応、顧客要望など)をセクションとして網羅します。
- セクションの独立性を保つ: AIは必要な部分だけを抜き出して参照することが多いため、各セクションが単独でも意味を成すように設計します。他セクションを参照する場合は「詳細は○○セクションを参照」と明示的にリンクを記載するとAIにとっての参照性が向上します。
- 専門用語集の充実: 社内独自の用語や略語が多い場合、専門用語集セクションを手厚くすることをお勧めします。
- たたき台との整合性: Step 1で作成するたたき台(アジェンダ)もこのフォーマットに沿った構成にすることで、ディスカッションの流れがそのままドキュメント構造に反映されます。
実行方法
実際の処理は以下の手順で実行します。Web UIから試行錯誤が可能なため、プロンプトの改善も非常にやりやすかったです。
- 動画のアップロード: Google Meet録画をGoogle Driveに保存
- Gemini Web UIでの処理: Web UIで動画を選択し、プロンプトを入力して実行
- 結果の確認と調整: 生成されたMarkdownを確認し、必要に応じて手動で微調整
コストと効率性
実際の運用実績として、30分〜1時間の動画をGeminiで処理した場合、処理時間は5〜10分程度で完了します。 Google Workspaceにバンドルされているため追加のLLM実行コストもなく、人的コストも録画準備に10分、レビューに20分程度と最小限です。
従来の手動ドキュメント作成では、歴史のあるシステムの複雑なコンテキストを把握するために複数メンバーへのヒアリングが必要で、さらに「書く」という行為自体の負荷も高いため、数時間かかることもありました。 本手法では、関係者が一堂に会して議論することでヒアリングの手間が省け、「話す」という単位時間あたりの情報量が多い行為を活用できるため、録画30分と準備・確認30分の合計1時間程度で完了します。 また、会話ベースのためゼロから書き起こす心理的ハードルが低く、継続的なドキュメント更新も行いやすいです。
また、一度作成したプロンプトは繰り返し使い回せるため、チーム全体で同じプロセスを採用でき、誰が実行しても同じ品質のドキュメントが生成されるというスケーラビリティと品質の一貫性も大きな利点となっています。
今後の展望:ドキュメントの自動更新
一度作成したドキュメントも、開発が進むにつれて古くなってしまうという課題があります。 この「情報の鮮度」を保つため、現在はGitHub Actionsを活用した自動ドキュメント更新の仕組みを試験導入しています。
具体的には以下のようなフローで、リリース間で発生した変更(PRの内容やレビューコメント)をAIに読み込ませ、domain_docs/ 配下のドキュメントを自動更新するPRを作成しています。

これにより、開発活動と連動してドキュメントが常に最新状態に保たれ、AIエージェントが古い情報に基づいて誤った提案をするリスクを減らせると考えています。 この自動更新の仕組みについても、別の機会にブログとして詳しく紹介できればと思います。
まとめ
AIエージェントを使いこなす鍵は、モデルの性能だけでなくコンテキストの質にあります。今回は、動画とGeminiを活用して暗黙知を低コストでコンテキスト化する手法を紹介しました。 本記事で紹介した事例は、執筆当時に利用可能だったGemini 2.5 Proを前提としたものですが、現在は後継のGemini 3.0 Proも利用可能で、さらに高精度な動画解釈が期待できます。
今後は、会議の録画ファイルの作成をトリガーにdocumentを更新するなど更なる効率化にもチャレンジする予定です。
AI Readyな組織へ
このコンテキスト作成の活動を通じてチームメンバー間でのナレッジ共有が進んだことも予想以上の恩恵となりました。 AIのための情報整備を進めることは、結果として人間のオンボーディングやナレッジ共有にも役立つことを改めて実感できました。
将来、より高性能なAIモデルが登場した際には、豊富で構造化されたコンテキストを持つ組織はその恩恵を最大限に享受できるでしょう。 本稿が皆さまのチームのコンテキスト整備の一助になりますと幸いです。
enechainでは、事業拡大のために共に挑戦する仲間を募集しています。興味がある方はぜひお声がけください!