

この記事はenechain Advent Calendar 2024の14日目の記事です。
はじめに
こんにちは。enechainで統計・機械学習モデルの構築やLLM(大規模言語モデル)の活用推進を担当している@udon_tempuraです。
私達のチームでは、以前紹介した会議動画要約のノウハウを活用し、 社内用の動画・音声文字起こしツールを構築・運用しています。 本記事では、その精度向上の仕組みについて紹介します。 実装も比較的少なく実現できたため、セキュリティなどの関係により内製で文字起こしを構築している方々の参考になれば幸いです。
背景と課題
社内用動画・音声文字起こしツールの構築において、当初はGeminiのみで音声文字起こしを実現していました。 Geminiはコンテキストベースの理解力に優れ、文脈から適切な専門用語を推測可能である一方で、 口調や文末の表現など細かい部分の文字起こしにおいて認識が不安定になるケースがありました。
会議の内容によっては、このレベルの品質では実用的な文字起こしの結果は得られません。 そこで、細かい部分の認識に強いCloud Speech-to-Textを組み合わせて解決を図ることにしました。
システム要件
以下の要件を満たすシステムの構築を目指しました。
- ドメイン固有の用語を高精度で認識できること
- 日本語特有の文末表現(述語や否定)や細かい口調の認識精度を向上させること
- 従来の音声認識システムの細かな認識精度と、生成AIのコンテキスト理解力を両立させること
- 待ち時間が長すぎるとUXを損ねるため、高速な処理を実現すること
システム実装
アーキテクチャ
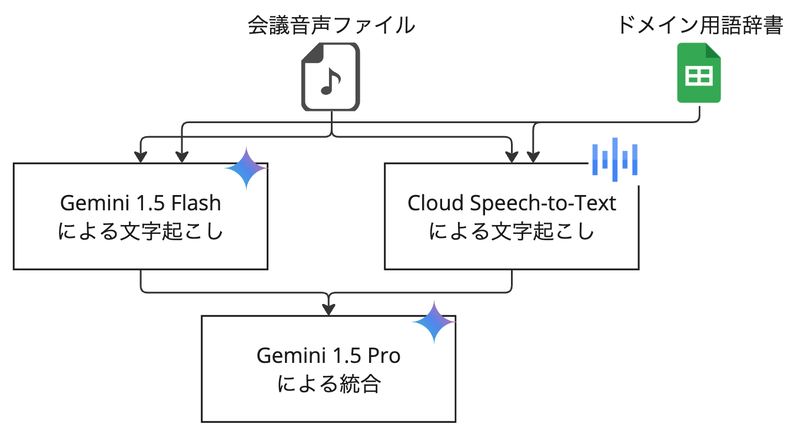
検討の結果、すべての処理をGoogle Cloudのサービス内で完結させる設計を採用しました。この選択には大きな利点がありました。
セキュリティ面では、データがGoogle Cloud外に出ないため、データ流出リスクを最小限に抑えることができます。 Google Cloudの強固なセキュリティ基盤を活用でき、コンプライアンス要件への対応も容易になりました。
コスト面では、他のLLMと比較してGeminiは価格競争力に優れており、大きな利点となりました。 従量課金制で使用量に応じた適切なコスト管理が可能であり、請求の一元管理により予算管理と費用対効果の測定が容易になりました。
技術面でも、Geminiの優れたマルチモーダル認識能力を活用できることが大きなメリットでした。 Cloud Speech-to-Textとの親和性が高く、連携が容易であることも重要な選択理由となりました。
入力データ形式
入力データは、動画ではなく音声ファイルを採用しました。 これは、動画データを含めた場合と比較して認識精度に大きな差が見られなかったことに加え、 処理に必要なトークン量を大幅に削減でき、コスト削減と処理速度向上を実現できるためです。
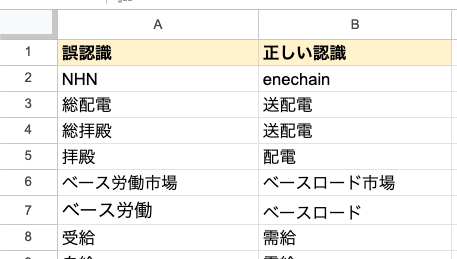
ドメイン固有用語の管理
ドメイン固有用語の管理は、スプレッドシートによって実現しています。 Cloud Speech-to-Textの認識ミスが多い用語を重点的に登録し、用語の追加・更新が容易なシンプルな形式を採用しました。 また、ドメイン用語への対応のため社内のユビキタス言語辞書を利用しており、定期的にドメイン用語スプレッドシートへの取り込みを行っています。
処理フロー
Cloud Speech-to-Textによる文字起こし
Cloud Speech-to-Textでは、頻出用語の認識ミスを抑制させるため、 辞書データを音声適応に与えて実行しています。 音声適応ブースト機能もありますが、 2024/12/06時点でpre-GAの機能であるため現時点では採用を見送っています。 (各機能の詳細については、リンク先のドキュメントをご参照ください)
from google.cloud import speech_v2 from google.cloud.speech_v2.types import cloud_speech import unicodedata # ドメイン固有用語の取得、音声適応のための整形 # ここは実際のスプレッドシートに従って変更してください google_spread_sheet_url = "https://docs.google.com/spreadsheets/d/spread_sheet_url" worksheet_name = "シート1" worksheet = gc.open_by_url(google_spread_sheet_url).worksheet(worksheet_name) phrase_list = worksheet.col_values(2)[1:] normalized_phrases = [unicodedata.normalize("NFKC", phrase) for phrase in phrase_list] # 音声適応のための設定作成 phrase_set = cloud_speech.PhraseSet(phrases=[{"value": phrase} for phrase in normalized_phrases]) adaptation = cloud_speech.SpeechAdaptation( phrase_sets=[cloud_speech.SpeechAdaptation.AdaptationPhraseSet(inline_phrase_set=phrase_set)] ) config = cloud_speech.RecognitionConfig( auto_decoding_config=cloud_speech.AutoDetectDecodingConfig(), adaptation=adaptation, language_codes=["ja-JP"], model="long", ) # request to Cloud Speech-to-Text API request = cloud_speech.RecognizeRequest( recognizer=f"projects/google_cloud_project_id/locations/global/recognizers/_", config=config, uri="gs://test_bucket/test_audio.mp4", ) response = speech_v2.SpeechClient().recognize(request=request)
また、長い音声が渡された場合は10MB単位に音声を分割し、並列処理することで処理時間の短縮を図っています。
Gemini 1.5 Flashによる認識処理
LLMでの文字起こしにはGemini 1.5 Flashを採用しています。 これは、処理速度を向上させることが目的です。 ここでは、Cloud Speech-to-Textで辞書データを音声適応に与えていたのと同様に、プロンプトに辞書情報を挿入することで用語認識精度を高めています。 こちらの論文を参考にしつつ試行錯誤した結果、辞書情報はpipe形式で挿入しています。 また、こちらも長い音声の場合は30分単位に分割して並列処理しています。 これは処理時間の短縮もありますが、LLMのoutput token limitを超過しないようにすること、 output token量が多くなると品質が不安定になる傾向があることへの対応が主な理由です。
def dict_to_pipe_table_prompt(domain_dict: dict) -> str: """ドメイン用語辞書をpipe形式のテーブル文字列に変換する""" # イテレータから最初のペアを取得 it = iter(domain_dict.items()) header_key, header_value = next(it) initial = "5. 以下に与える辞書は頻出する認識間違いです。この情報を元に認識間違いを最小化してください。 \n" # ヘッダ行と区切り行 header = f"| {header_key} | {header_value} |\n" # 残りの行 rows = "" for k, v in it: rows += f"| {k} | {v} |\n" return initial + header + rows # ワークシートから全データを取得 data = worksheet.get_all_values() domain_dictionary = {row[0]: row[1] for row in data} str_pipe_table = dict_to_pipe_table_prompt(domain_dictionary) prompt=f""" この音声は、ある会議の音声です。この音声を、日本語で文字起こししてください。 # 制約 1. 発言内容はそのままに、フィラーや言い淀みなど、意味のない部分のみ削除してください。 2. 読みやすいように、話題や文章の間に改行を入れてください。 3. 不要な空白を挟まないでください。 4. 出力は純粋な文字起こしのみとし、それ以外の情報や注釈は含めないでください。特に専門用語の補足説明を勝手に追加しないでください。 {str_pipe_table} """
Gemini 1.5 Proによる統合
結果のマージ処理はLLMに任せる方式を採用しました。 マージには高度な処理が必要となるため、Gemini 1.5 Proを利用しています。 これにより、文脈の一貫性を保ちながら、高品質な統合結果を得ることができています。
prompt=f"""\ # 前提 あなたは日本語のテキスト最適化と自然言語処理の専門家です。特に、日本の電力取引に関連する専門用語と文脈に精通しています。 あなたの任務は、音声からの文字起こしを改善し、修正することです。 transcript_llmとtranscript_s2tというラベルの付いた、同じ音声コンテンツの2つの異なる文字起こしが提供されます。 これらの文字起こしを比較し、エラーを修正し、テキスト全体の品質と自然さを向上させた最適化版を作成することがあなたの仕事です。 以下のガイドラインに従ってください。 1. transcript_llmとtranscript_s2tを比較して、相違点を特定してください。 2. どちらの文字起こしにも見つかった誤字脱字や文法エラーを修正してください。 3. 各文や表現について、最も正確で自然な響きのあるバージョンを選択してください。 4. 特に各チャンクの冒頭と末尾で、テキストの流れと一貫性を確保してください。 5. 一方の文字起こしに明らかな間違いや省略があり、もう一方で修正されている場合は、修正されたバージョンを使用してください。 6. 発言の元の意味と意図をできるだけ維持してください。 7. 両方の文字起こしが特定の表現で一致していても不自然に聞こえる場合は、より自然な代替案を提案してもかまいません。 8. トークン制限により、入力がより大きな文字起こしの一部である可能性があることに注意してください。 # 制約 1. 2つの文字起こしを比較し、最も正確で自然な表現を選択してください。 2. 誤字脱字や文法エラーを修正してください。 3. 専門用語や表現が適切に使用されていることを確認してください。 4. テキストの一貫性を保ちながら、元の発言の意味や意図を維持してください。 5. 最適化された文字起こしのみを出力してください。追加の説明や分析は不要です。 6. transcript_llmとtranscript_s2tに何も文字列が格納されていない場合、空文字列を返してください。 7. 可能な限りフィラーは除去してください。 8. 出力は純粋な文字起こしのみとし、それ以外の情報や注釈は含めないでください。特に専門用語の補足説明を勝手に追加しないでください。 # 処理内容 以下の2つの文字起こしを比較し、最適化された単一の文字起こしを作成してください。 transcript_llm: {transcript_llm} transcript_s2t: {transcript_s2t} """
現状の課題と展望
Geminiのリソース制約
Geminiにはproject単位のAPIコールリミットの他に、Google Cloud全体のGeminiのコンピューティングリソースのリミットが存在しており、 予期せぬタイミングでエラーが発生することがあります。 この問題はリソース予約によって回避可能ですが、非常に高額なためretryを実装することで対応しています。 このため、余分な待ち時間が発生しているのが現状です。
処理プロセスの最適化
現状、処理速度を鑑みて音声データで処理を実行しており、Geminiの強みである動画をインプットにした処理が実現できていません。 画面共有にて資料投影する会議では、動画そのままの処理のほうが有効なため、精度追求の観点ではこちらも改善の余地がある状況です。 また、Cloud Speech-to-Textを利用することで精度向上できますが、LLM単体と比較してコストが高くなることも課題です。
ただし、これらの課題は技術の進歩、特にLLMの性能向上によって解決される可能性が高いです。 会議という一定フォーマットの決まった議論の文字起こしは、LLMによる処理一発で解決できるようになるのもそう遠くないのではと考えています。 現に、2024/12/12に発表された Gemini 2.0 Flashを文字起こしモデルにして実験したところ、顕著な品質改善が見られました。 もう少し検証は必要ですが、Gemini 2.0 Flashのみの文字起こしでも問題ない品質が得られるのではと期待しています。
重要なのは、現時点で活用できる技術を最大限に活かし、実用的なシステムを作り上げ、将来の発展につながる知見や経験を積み重ねることだと思います。
おわりに
既存の音声認識技術と最新の生成AIを組み合わせることで、高精度な文字起こしを実現できました。 いくつか課題もありますが、現時点でも十分に実用的なソリューションとして活用が期待できると考えています。
今後もLLMの活用を積極的に進め、より良いソリューションの開発に取り組んでいきたいと思います。 本記事が、同様の課題に直面している組織の皆様にとって、課題解決の一助となれば幸いです。
enechainでは、事業拡大のために共に挑戦する仲間を募集しています。興味がある方はぜひお声がけください!